
To continue our series on AI for Ecommerce, let's now look at how we can maximize the revenue of an online store with a reinforcement learning algorithm called Thompson Sampling.
In this project we're going to assume the online store has many existing customers, and the goal of the AI is to get the maximum number of customers to subscribe to a premium plan, either yearly or monthly.
A real-world example of this would, of course, be Amazon Prime.
The reason we're going to use the Thompson Sampling reinforcement learning algorithm is because it is the most powerful algorithm for a specific type of problem called the multi-armed bandit problem.
This is a great algorithm to learn as the multi-armed bandit problem can be applied to many real-world business challenges.
This article is based on notes from this course on AI for Business and is organized as follows:
- Defining the Environment
- Intuition & Theory of Thompson Sampling
- Implementation in Python
Stay up to date with AI
1. Defining the Environment
Before we get to the environment, let's first define the problem we're trying to solve.
Problem Definition
As mentioned, the problem we're trying to solve is a maximization problem where we're trying to get the maximum number of customers to join the company's premium plan.
In order to convert customers to the premium plan, let's assume the marketing team came up with 9 different strategies, each with 4 features.
Each of the features will be different for each strategy, but in general will include include:
- A sign-up form
- A package - this is the offer for the premium plan
- An ad - the ad could be an email, or on a platform like Facebook or Google
- A special deal - each time the customer is offered the premium plan we'll have a unique special deal to sell it, for example first 3 months free
Our goal with our Thompson Sampling algorithm is then to find which one of these 9 strategies performs the best in converting customers to the premium plan.
It's important to note that for the multi-arm bandit problem we only need to define actions and rewards, and not states.
Another important point is that we're going to be doing online learning, meaning we're going to experiment with the 9 strategies customer by customer.
The reason we don't need to define a state is because each customer that is shown one of the strategies is considered the state.
Defining the Actions
As you may have guessed, the action for this environment is simply deploying one of the 9 strategies. Initially it will be chosen randomly since we have no data, and then we will use Thomson Sampling to optimize this over time.
Defining the Rewards
The rewards are quite easy to define for this problem, because whichever strategy we use on the customer, we will either get a reward of 1 if they subscribe to the premium plan, or a 0 if they do not.
One other consideration is that we want to find the best strategy as fast as possible, since deploying each strategy to customers has costs.
2. Intuition & Theory of Thompson Sampling
To understanding Thompson sampling we first need to understand the multi-armed bandit problem.
Multi-Armed Bandit Problem
First, let's start with a one-armed bandit - a one-armed bandit is a slot machine.
The one-armed part of the name refers to the old slot machines where you had to pull a lever to start the game, and the bandit comes because this is one of the quickest ways to lose your money in a casino.

Now, a multi-armed bandit is the challenge you're faced when you come up to multiple of these machines.
So the question is how do you play multiple of these machines to maximize your returns? Here is a good diagram of the problem we're facing from Towards Data Science:
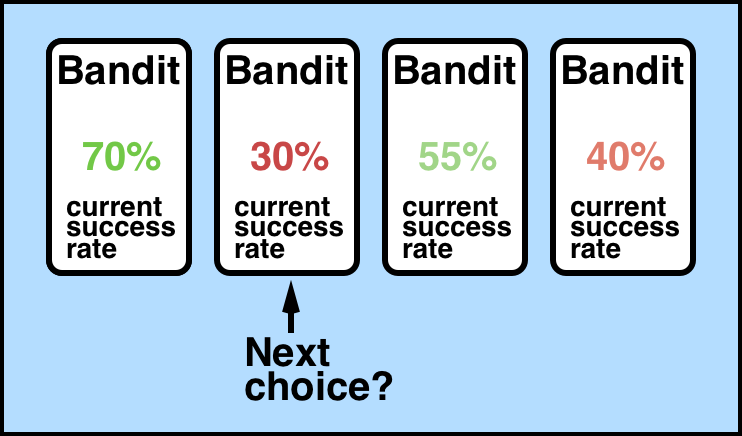
The assumption is that each of these machines has a distribution of outcomes, but the problem is that you don't know these distributions in advance.
So the goal is to figure out which of the bandits has the most favorable distribution.
Here's an example of the possible distributions from StackExchange:
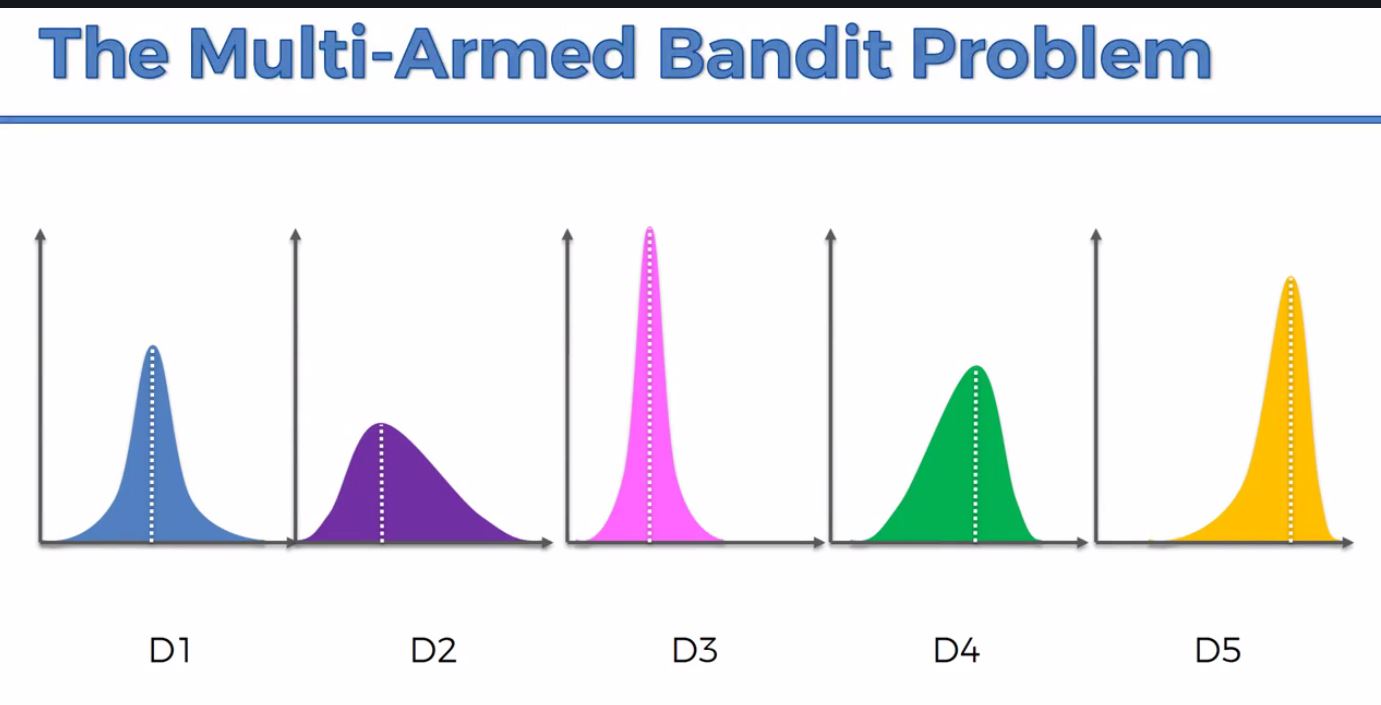
The tradeoff is that the longer you take to figure out the best distribution, the more money you will lose on the bandits with unfavorable distributions.
This is referred to as the exploration-exploitation dilemma - you need to explore the machines to figure out the distribution, but you also need to exploit your current findings as quickly as possible.
This is a tradeoff because if you explore for too long and don't exploit your knowledge, this is referred to as regret. But if you exploit your findings too early, you may be using a sub-optimal machine and not know it because you didn't explore enough.
Here is a quick summary of the multi-armed bandit problem that we're going to solve:
- We have $d$ arms, in our example we have $d$ conversion strategies
- Each time a user goes on the website, this is a round
- At each round $n$, we choose one strategy to display to the user
- At each round $n$, strategy $i$ gives reward $r_i(n) \ \epsilon \ \{0,1\}: r_i(n) = 1$ if the user converted with strategy $i$, and 0 if they did not
- Our goal is to maximize the total reward we get over many rounds
Now let's move on to the intuition of the Thompson sampling algorithm.
Intuition of the Thompson Sampling Algorithm
As mentioned, each of the strategies will have a distribution associated with it and we need to explore each strategy to get data about them.
Based on the returns from the trials, the Thompson sampling algorithm will start to construct a distribution for each strategy.
These distributions are not actually trying to guess the distribution behind the strategy, instead the algorithm is constructing distributions about where it thinks the actual expected value might be.
The distributions are where we mathematically think the $\mu*$ values will be - the key point is that we are not trying to guess the distributions behind the strategies.
This feature demonstrates that Thompson sampling is a probabilistic algorithm, versus the upper-confidence bound which is deterministic.
By doing it this way we have generated our own bandit configuration for the expected reward.
With each new round and new data we get we update our perception of the underlying probability distribution, and we keep doing this until we've refined the distributions substantially.
Now that we understand the multi-armed bandit problem and how we can used Thompson sampling to solve it, let's move on to the Python implementation.
3. Python Implementation of Thompson Sampling
For the Python implementation of the Thompson sampling algorithm we're going to make use of Google Colab.
We're also going to create a simulation for the conversion rate of the 9 different strategies, and the algorithm will find the best one. In this simulation, strategy 7 will have the highest conversion rate of 20%.
Project Setup
The first step as usual will be to import the necessary libraries, in this case we just need numpy, matplotlib, and random:
# Import the libraries
import numpy as np
import matplotlib.pyplot as pltNext we need to set our parameters, which are the total number of rounds that we'll use in the experiment N, and the number of strategies we're going to test d:
# Set the parameters
N = 10000
d = 9Now we're going to create the simulation for conversion rate of the 9 strategies. This will be an array of the total rounds, and for each of them we'll simulate which strategy converts.
We first set the conversion rates, and then we use a numpy array initialized with 0's. We then write a for loop to populate the rows correctly with 1's when the strategy converts, and then another for loop for the columns.
To simulate whether we get a 0 or a 1 in our for loops we're going to make use of a Bernoulli distribution. So if we're dealing with strategy 1 we take a random draw of Bernoulli distribution with a 5% chance of being 1 and 95% chance of being 0:
# Create the simulation
conversion_rate = [0.05, 0.13, 0.09, 0.16, 0.11, 0.04, 0.20, 0.08, 0.01]
X = np.array(np.zeros([N,d]))
for i in range(N):
for j in range(d):
if np.random.rand() <= conversion_rate[j]:
X[i,j] = 1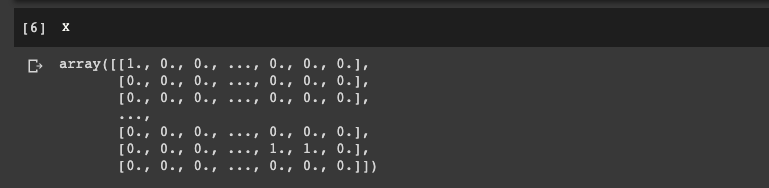
Here we can see each row corresponds to a user connecting to the website, and we can see for this simulation strategy 1 converted for the first user.
Now we're ready to implement the Thompson sampling algorithm.
Implement Thompson Sampling
In addition to the Thompson sampling algorithm, we're also going to implement a random strategy so that we have a benchmark to compare the model to.
To get started, the first step for Thompson sampling is to take random draw for each strategy $i$ from the following beta distribution:
\[\theta_i(n) ~ \beta(N_i^1(n) + 1, N_i^0(n) + 1)\]
To implement this we're going to use the random module, which will return a sample from the beta distribution.
We also need to initialize 6 variables - 3 for the random strategy and 3 for Thompson sampling. The 3 variables will be the same for each and will be
- A list of the strategies
- The total reward accumulated over the rounds
- The reward we get at each round
We also need to initialize 2 extra variables just for Thompson sampling, which are:
- $N_i^1(n)$ is the number of times the strategy $i$ has received a 1 reward up to round $n$
- $N_i^0(n)$ is the number of times the strategy $i$ has received a 0 reward up to round $n$
To do this we'll create 2 lists for these numbers.
# Implement a Random strategy & Thompson Sampling
strategies_selected_rs = []
strategies_selected_ts = []
total_reward_rs = 0
total_reward_ts = 0
numbers_of_rewards_1 = [0] * d
numbers_of_rewards_0 = [0] * dNow that we have initialized these variables we will write a for loop to repeat the 3 steps we need to take for the Thompson sampling algorithm.
In our for loop the second step is to select the strategy $s(n)$ that has the highest $\theta_i(n)$. For step 3 we then update $N_{s(n)}^1(n)$ and $N_{s(n)}^0(n)$.
for n in range(0, N):
# Random Strategy
strategy_rs = random.randrange(d)
strategies_selected_rs.append(strategy_rs)
reward_rs = X[n, stragey_rs]
total_reward_rs += reward_rs
# Thompson Sampling
strategy_ts = 0
max_random = 0
for i in range(0, d):
random_beta = random.betavariate(number_of_rewards_1[i] + 1, numbers_of_rewards_0[i] + 1)
if random_beta > max_random:
max_random = random_beta
strategy_ts = i
reward_ts = X[n, strategy_ts]
if reward_ts == 1:
number_of_rewards_1[strategy_ts] += 1
else:
number_of_rewards_0[strategy_ts] += 1
strategies_selected_ts.append(strategy_ts)
total_reward_ts = total_reward_ts + reward_tsNow that we've implemented the Thompson sampling algorithm we're ready to compute the final results to see how well it performed against the benchmark.
To compare the two strategies we're going to use the absolute and relative return.
As we can see from Investopedia:
Relative return is the return an asset achieves over a period of time compared to a benchmark.
In our case the asset is Thompson sampling and the benchmark is the random strategy. We're going to use the absolute return for the difference in strategies to compute the relative return - or what % Thompson outperforms the random strategy.
# Compute the Absolute & Relative Return
absolute_return = (total_reward_ts - total_reward_rs)*100
relative_return = (total_reward_ts - total_reward_rs) / total_reward_rs * 100
print("Absolute Return: ${:.0f}".format(absolute_return))
print("Relative Return: {:.0f}%".format(relative_return))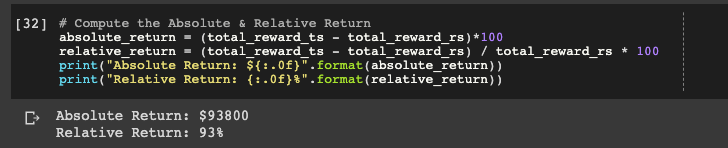
Here we can see we made $92800 more in absolute return with Thompson Sampling and it performed 93% better than the benchmark.
Let's change one of the parameters - the number of rounds N - to 100,000 and see what we get:
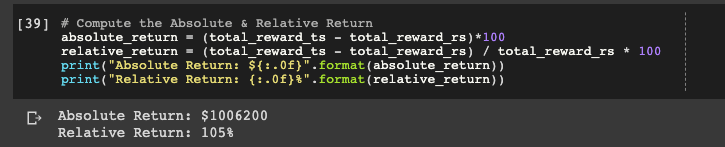
Here we can see the Thompson sampling strategy made more than $1 million for our fictional eCommerce business.
Plotting a Histogram of the Selections
The last step in this project is to plot a histogram of the selections made to see how fast the Thompson sampling algorithm is able to identify the strategy with the highest conversion rate.
plt.hist(strategies_selected_ts)
plt.title('Histogram of Selections')
plt.xlabel('Strategy')
plt.ylabel('Number of times the strategy was selected')
plt.show()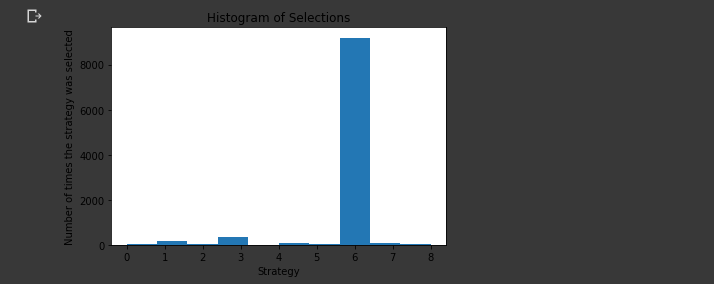
Here we can see strategy 7 was selected the most as it had the highest conversion rate.
Summary: Thompson Sampling for Maximizing Revenues
In this guide we looked at how we can maximize revenue for an eCommerce business using the reinforcement learning algorithm: Thompson sampling.
The reason we used Thompson sampling is that it is a powerful algorithm for the multi-armed bandit problem.
Specifically, the problem we solved was a maximization problem where we tried to convert as many customers as possible to a premium subscription plan.
The company had 9 different strategies to test, each with 4 features.
As discussed, the Thompson sampling algorithm works by constructing a distribution associated with each strategy. This means that Thompson sampling is a probabilistic algorithm.
After implementing the Thompson sampling algorithm in Python we saw that it was able to identify the strategy with the highest conversion rate and achieve a 93% better performance than the benchmark with 10,000 rounds.


