

In this article, we'll continue our fine-tuning GPT-3 series with a new dataset: food reviews on Amazon. In particular, we'll go through several OpenAI example notebooks to get a better understanding of how we can use embeddings.
The OpenAI Embeddings API is a key component of fine-tuning GPT-3 as it allows you to measure the relatedness of different text strings. These embeddings can then be used for a number of use cases, including:
- Search
- Clustering
- Recommendations
- Anomaly detection
- Classification
- Regression, and so on
As OpenAI highlights:
An embedding is a vector (list) of floating point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
The steps we will take include:
- Obtain the dataset
- Calculate embeddings and save them for future use
- Semantic search using embeddings
- Classification using embeddings
- Regression using embeddings
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
1. Obtain the dataset
The first notebook we'll go through contains the datase we'll be using, which contains 500,000+ food reviews on Amazon. We'll just use a subset of 1k of the most recent reviews for this tutorial.
As we can see below, each review has the following data: Time, ProductId, UserId, Score, Summary, and Text.
import pandas as pd
input_datapath = 'https://raw.githubusercontent.com/openai/openai-cookbook/main/examples/data/fine_food_reviews_1k.csv' # to save space, we provide a pre-filtered dataset
df = pd.read_csv(input_datapath, index_col=0,on_bad_lines='skip')
df = df[['Time', 'ProductId', 'UserId', 'Score', 'Summary', 'Text']]
df = df.dropna()
df['combined'] = "Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
df.head(2)
Next up, we'll take a subsample of 1k reviews from this dataset and removes reviews that are too long:
# subsample to 1k most recent reviews and remove samples that are too long
df = df.sort_values('Time').tail(1_100)
df.drop('Time', axis=1, inplace=True)
from transformers import GPT2TokenizerFast
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
# remove reviews that are too long
df['n_tokens'] = df.combined.apply(lambda x: len(tokenizer.encode(x)))
df = df[df.n_tokens<8000].tail(1_000)
len(df)
Stay up to date with AI
2. Calculate embeddings and save them for future use
In order to calculate the embeddings for our Amazon reviews, we first need to import OpenAI and set our API key:
import openai
from openai.embeddings_utils import get_embedding
openai.api_key = "YOUR-API-KEY"Next, we'll use the get_embedding function and the Ada model to calculate the embeddings, and finally, we'll save them to CSV for future use:
# This will take just between 5 and 10 minutes
df['ada_similarity'] = df.combined.apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
df['ada_search'] = df.combined.apply(lambda x: get_embedding(x, engine='text-embedding-ada-002'))
df.to_csv('/content/fine_food_reviews_with_embeddings_1k.csv')Now that we have a CSV file of our embeddings, we can use these for several use cases, let's start with semantic search.
3. Semantic search using embeddings
One of the ways we can use our embeddings is semantic search, which enables us to search through all reviews very efficiently and cost-effectively.
To do so, we just need to also embed the user's search query and then use our pre-saved embeddings to find the most similar ones.
First, let's start by reading in our embeddings CSV with Pandas and creating a new column in the dataframe called ada_search. The values in this column are the result of applying two functions to the values in the ada_search column:
- The
eval()function evaluates a string as a Python expression and returns the result. - The
np.array()function fromnumpyis applied, which converts the resulting value from step 1 into a numpy array.
import pandas as pd
import numpy as np
datafile_path = "/content/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["ada_search"] = df.ada_search.apply(eval).apply(np.array)Next, we're going to create a search_reviews function to search through all review embeddings and find similar products.
As the notebook highlights, we compare the cosine similarity of the embeddings of the query and the documents (in this case reviews), and show top_n best matches.
Here's what the code below does is:
- Searches through a DataFrame of reviews (
df) for a specific product based on a providedproduct_description - The function uses OpenAI's
get_embeddingfunction to get the embedding of theproduct_description. - The function then applies the
cosine_similarityfunction to each review in theada_searchcolumn of the DataFrame and calculates the similarity between the embedding of theproduct_descriptionand each review. - The resulting similarities are stored in a new column called
similarities. - The DataFrame is then sorted in descending order based on the
similaritiescolumn and the topnrows are selected. - The
combinedcolumn of these rows is modified by removing the substrings "Title: " and "; Content:" and the resulting strings are printed (ifpprintis True) or returned.
from openai.embeddings_utils import get_embedding, cosine_similarity
# search through the reviews for a specific product
def search_reviews(df, product_description, n=3, pprint=True):
embedding = get_embedding(
product_description,
engine="text-embedding-ada-002"
)
df["similarities"] = df.ada_search.apply(lambda x: cosine_similarity(x, embedding))
res = (
df.sort_values("similarities", ascending=False)
.head(n)
.combined.str.replace("Title: ", "")
.str.replace("; Content:", ": ")
)
if pprint:
for r in res:
print(r[:200])
print()
return res
res = search_reviews(df, "delicious beans", n=3)
res = search_reviews(df, "bad delivery", n=1)
As we can see, we can now easily search the embeddings semantically and find related reviews to our query.
4. Classification using embeddings
Next, let's use our embeddings for a classification task i.e. to predict one of the predefined categories based on a given input.
In this case, we're going to predict the review score based on the text, and only if the algorithm predicts the exact number of stares will it be deemed correct.
To do so, the code below uses the Random Forest algorithm to predict the Score (a rating) of a product based on its embedding similarity (ada_similarity) to a product description.
Here's an overview of how this code from the OpenAI notebook works for classification:
- First, we appy the
evalfunction to theada_similaritycolumn to convert the strings to arrays. - The
train_test_splitfunction from Scikit-Learn is used to split the data into a training set (X_train,y_train) and a test set (X_test,y_test) - 20% is used for testing in this case. Therandom_stateparameter sets the random seed for the data split, ensuring reproducible results. - The
RandomForestClassifierclassifier is initialized withn_estimators=100, which specifies the number of trees in the forest. The classifier is then fit to the training data using thefitmethod. - The classifier is used to make predictions on the test set using the
predictmethod and the predicted labels are stored in thepredsvariable. - The
predict_probamethod is used to predict the probability of each label for each sample in the test set and the resulting probabilities are stored in theprobasvariable. - Finally, the
classification_reportfunction is used to generate a report of the classifier's performance on the test set. The report includes precision, recall, and F1-score for each label, as well as the overall accuracy:
df["ada_similarity"] = df.ada_similarity.apply(eval).apply(np.array)
X_train, X_test, y_train, y_test = train_test_split(
list(df.ada_similarity.values), df.Score, test_size=0.2, random_state=42
)
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
probas = clf.predict_proba(X_test)
report = classification_report(y_test, preds)
print(report)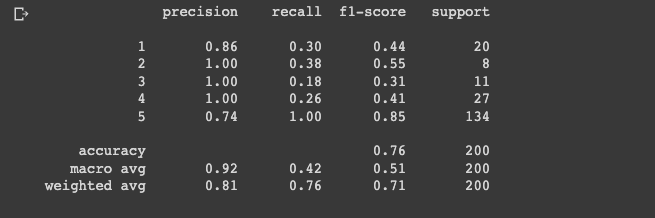
Here we can see the model has learnt how to distinguish between the categories decently well.
Next, up, let's visualize our classification results:
- The code below uses the
plot_multiclass_precision_recallfunction from OpenAI'sembeddings_utilsmodule to plot the precision-recall curves for a multiclass classification problem. - The
plot_multiclass_precision_recallfunction plots the precision-recall curve for each class in the list of labels and shows the overall average precision.
In case you need a refresher on precision and recall:
Precision is the fraction of true positive predictions among all positive predictions made by the classifier. Recall is the fraction of true positive predictions made by the classifier among all actual positive samples. The precision-recall curve plots precision on the y-axis and recall on the x-axis for different classification thresholds. A higher curve corresponds to a classifier that makes more accurate positive predictions.
from openai.embeddings_utils import plot_multiclass_precision_recall
plot_multiclass_precision_recall(probas, y_test, [1, 2, 3, 4, 5], clf)
From this chart, we see the 5-star (purple line) and 1 star (blue line) have the highest accuracy i.e. are the easiest to predict, which makes sense intuitively.
5. Regression using embeddings
In the next OpenAI notebook, we'll use our embeddings for regression, which means predict a number instead of categories. In this case, we'll predict a review score based on the text embeddings.
In this example, again we'll use the Random Forest algorithm to predict the Score (a rating) of a product based on its embedding similarity (ada_similarity) to a product description.
Here's an overview of what code below does:
- Again we use the
train_test_splitfunction to split the data into training and test sets - The
RandomForestRegressorregressor is initialized withn_estimators=100, which specifies the number of trees in the forest. - The regressor is then fit to the training data using the
fitmethod. - The regressor is used to make predictions on the test set using the
predictmethod and the predicted values are stored in thepredsvariable. - The
mean_squared_errorandmean_absolute_errorfunctions are used to calculate the MSE and MAE of the predictions on the test set. - MSE and MAE are common metrics for evaluating the performance of regression models. The MSE is the average squared difference between the predicted values and the true values, and the MAE is the average absolute difference between the predicted and true values.
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
X_train, X_test, y_train, y_test = train_test_split(list(df.ada_similarity.values), df.Score, test_size=0.2, random_state=42)
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)
mse = mean_squared_error(y_test, preds)
mae = mean_absolute_error(y_test, preds)
print(f"Ada similarity embedding performance on 1k Amazon reviews: mse={mse:.2f}, mae={mae:.2f}")Ada similarity embedding performance on 1k Amazon reviews: mse=0.64, mae=0.53
We can see the embeddings can be used to predict review scores with an average error of 0.60 per score prediction, which as the notebook highlights is roughly equivalent to predicting 1 out of 3 reviews perfectly, and 1 out of two reviews by a one-star error.
Summary: Fine-tuning GPT-3 using embeddings
In this article, we discussed how to use OpenAI's Embeddings API and GPT-3 to analyze food reviews from Amazon.
The Embeddings API allows you to measure the relatedness of different text strings and can be used for tasks such as search, classification, regression, and so on.
In the article, we went through several notebooks related to fine-tuning GPT-3 using embeddings, including:
- How to calculate embeddings and save them for future use
- How to use these saved embeddings for semantic search by finding the most similar reviews to a given product description
- How to use embeddings for classification, specifically predicting a review score label based on the review
- How to use the embeddings for regression by predicting a numberic review score based on the review text
Resources
- OpenAI cookbook: obtain the dataset
- Semantic text search using embeddings
- Classification using embeddings
- Regression using embeddings




