Sentiment analysis and natural language processing (NLP) is one of the most widely used applications of machine learning for trading and investing.
With the sheer amount data available on equities, NLP allows investors to efficiently gauge the overall sentiment as well as individual language metrics from a massive corpus of text data.
In this guide, we'll discuss exactly how traders and investors can use sentiment analysis and NLP for SEC filings to speed up their research process and potentially uncover alpha-generating ideas.
In particular, we'll review a few of the key findings from this paper on The Positive Similarity of Company Filings and the Cross-Section of Stock Returns, which states:
It is already well-documented that textual analysis of 10-K & 10-Qs can be largely profitable. This research studies the similarity of language used in the filings using data which enables to analyze what type of language is similar. Results show that the similarity of the positive language is the most profitable option.
In other words, the paper examines the similarity of language between filings and suggests that the lowest positive similarity stocks tend to outperform the highest positive similarity stocks. We'll also discuss possible explanations for this anomaly below.
In terms of the data used for the paper, the exact data source can be found in the MLQ app, which as you can see below has a section for SEC filing sentiment analysis:
Disclaimer: The views and opinions expressed by the author are for informational purposes only and do not constitute financial, investment, or other advice.
Introduction to Sentiment Analysis for SEC Filings
One of the most interesting applications of machine learning for investing is using natural language processing to analyze periodic reports that publicly traded companies, otherwise known as 10-Ks (annual) and 10-Qs (quarterly).
With the increasing volume of text data that analysts need to read through, advances in machine learning offer a data-driven approach to efficiently analyze these filings.
In particular, sentiment analysis and NLP can be used to identify the type of language used in the filing, for example, if it contains litigious language, constraining language, and so on.
These language metrics can also be used to analyze the similarity and differences with the language used in previous reports. These similarity and difference metrics can then alert investors to major changes at the company that may warrant further analysis.
As this paper highlights in regards to language similarities and differences:
The highest (lowest) similarity decile is not always the most profitable (unprofitable). This paper is focused on the usability of a positive similarity score in a trading strategy.
The general idea of using these metric in a trading strategy is that a low similarity of positive language metrics can positively impact future performance of the company.
In other words, by providing new (dissimilar) positive language, the author finds a clear pattern where companies with the lowest similarity scores outperform companies with the highest positive similarity.
Stay up to date with AI
The authors mention that the idea of using changes in language metrics was previously reported in a paper titled Lazy Prices. This paper asserts that when companies make active and significant changes in their reporting, this provides an important signal about future performance. As the authors write:
Changes to the language and construction of financial reports also have strong implications for firms’ future returns: a portfolio that shorts “changers” and buys “non-changers” earns up to 188 basis points in monthly alphas (over 22% per year) in the future.
The author of the positive similarity paper describes three main differences in their research:
- Their analysis is focused on the similarity of positive language only
- The holding period is one month compared to three months in Lazy Prices
- The investment universe is comprised of 1000 large cap US stock vs. 4000 stocks in Lazy Prices
The authors highlight their reasoning for these differences is both simplicity and diversification.
Not only does the author find a statistically significant alpha return from this strategy, but they assert that the effect seems to be an uncorrelated anomaly:
The effect seems to be an anomaly, since the strategy has a low correlation to the common equity risk factors (value, size, momentum, investments or profitability) and is uncorrelated to the market factor. Moreover, the alpha from common asset pricing models is both economically and statistically significant.
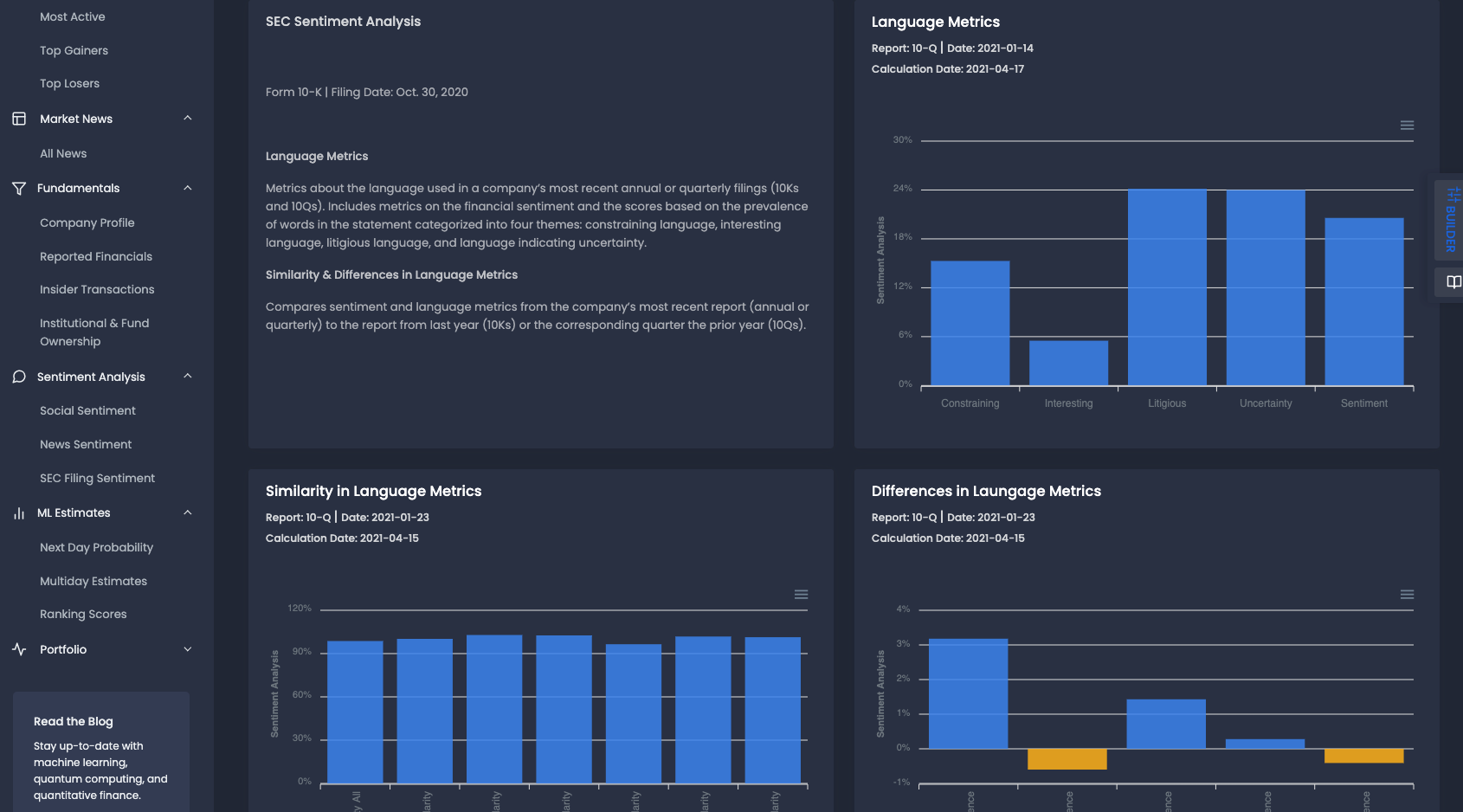
Data: Similarity in Language Metrics
The data for this paper is provided by Brain Company, which is the same data provider that powers SEC filing sentiment analysis in the MLQ app.
The company monitors a number of language metrics for both 10-Ks and 10-Qs and calculates sentiment scores for metrics such as:
- Constraining language
- Interesting language
- Litigious language
- Uncertain language
- Overall sentiment
- Positive and negative similarity
- Positive and negative differences
The sentiment scores for each language metric are calculating by analyzing the percentage of words that belong belong to that class. These metrics are also compared with previous reports in order to provide similarity and differences in language metrics.
The paper in question is focused on developing a trading strategy using the similarity of positive language between reports, which is provided in the bottom left:
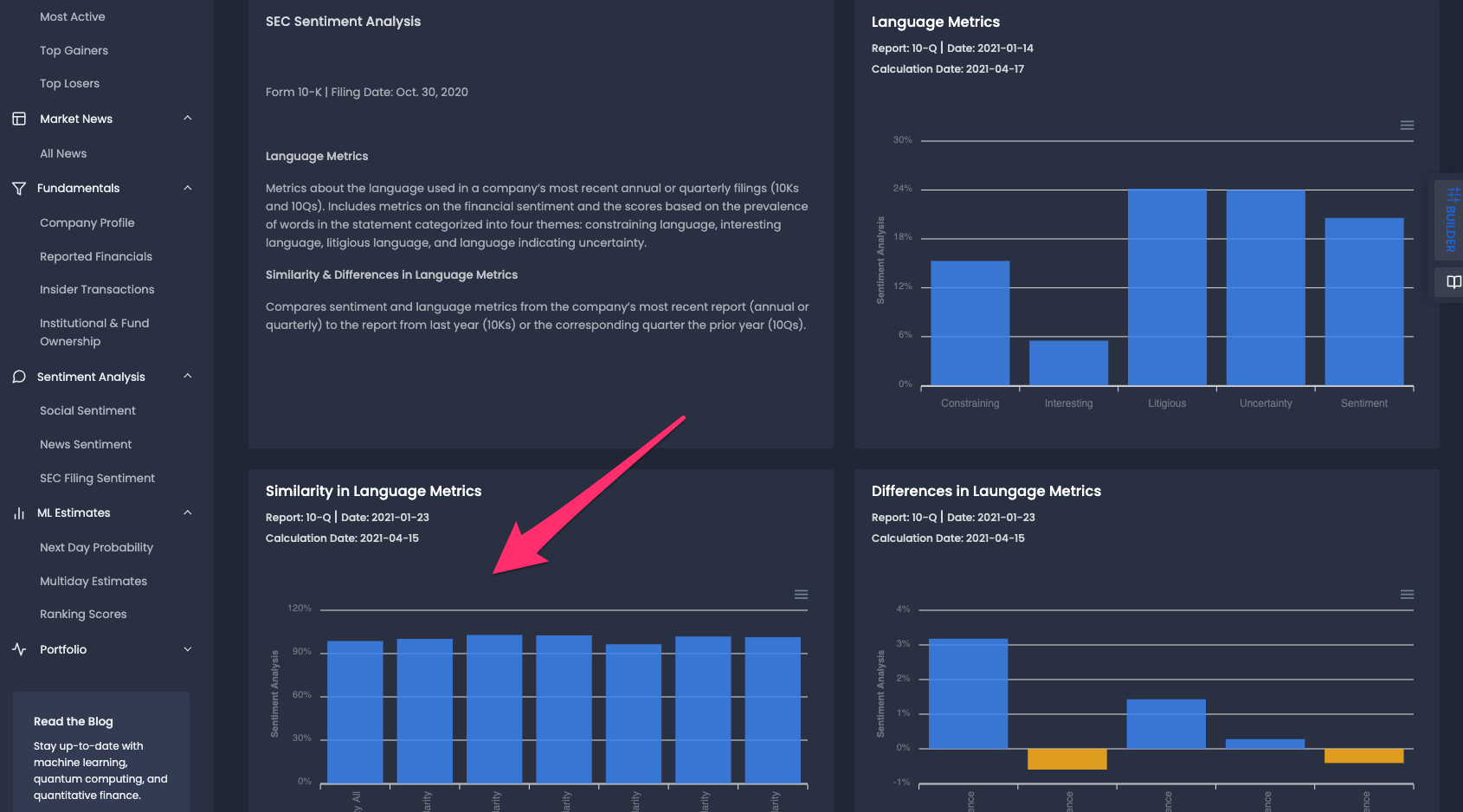
Developing a Trading Strategy with SEC Filings Sentiment & Positive Similarity
In order to use positive similarity to develop a trading strategy, the author first sorts stocks into deciles and reviews their performance.
Below you can see how stocks are ranked each month according to their positive similarity, as well as their one month return and standard deviation:

As you can see, in general the return declines as the decile increases, which indicates that stocks with low positive similarity tend to outperform those with high positive similarity.
The author suggests the following trading strategy to take advantage of this:
One viable strategy could be going long the first or even the first three deciles. Either used as a standalone strategy or in a portfolio as a building block, the investor could profit from the edge.
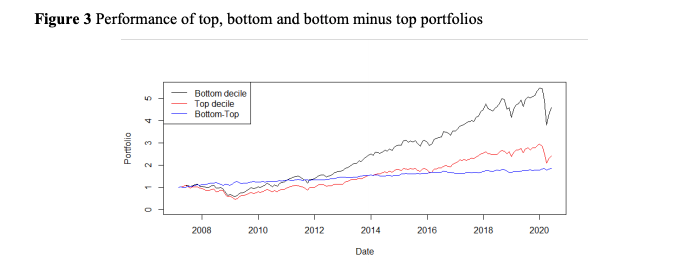
In addition to the potential return of this strategy, the author highlights that it is uncorrelated with the market. In particular, the results show that the alpha generated is both economically and statistically significant.
As the author states:
The strategy is, to a small extent, negatively correlated with value and investment factors, and positively correlated with the momentum factor. To some extent, the strategy is correlated with common equity factors, but they probably cannot explain the performance.
In the next section, we'll review a few possible explanations for the alpha of this strategy.
Possible Explanations
The first possible explanation presented is that companies are motivated to change the positive language in a filing if they believe it will positively influence investors.
Therefore, the hypothesis is that the effort to change the positive language should positively impact subsequent returns because management does not have the motivation to change report if it would harm the company significantly.
In short, there are three possible explanations for this anomaly:
- It can signal a new piece of possible information presented in the filing
- Changes in the language used in reports may reflect better governance of the company
- The language may simply be a from of manipulation, in which case a reversal in the long term is likely
Summary: Sentiment Analysis for SEC Filings
In summary, using sentiment analysis for textual analysis of 10-Ks and 10-Qs can add both an economically and statistically significant return to portfolio.
According to the research presented in this paper, preliminary results show that a low positive similarity in language metrics can be an important indicator of future performance. In particular, the author suggests that by going long the lowest similarity stocks can provide alpha for a portfolio.
Regardless if the trading strategy presented in this paper is used, sentiment analysis for SEC filings can drastically increase an analysts efficiency when it comes to reading through each report of the companies they're following.
In summary, this paper provides an interesting use case of modern machine learning in trading and investing. Since not many investors are currently applying sentiment analysis and NLP in their investment research, this presents early-adopters with a unique opportunity to get ahead of their peers and take advantage of these advances in AI and machine learning.
If you want to learn more about how machine learning can be applied to investment research, check out the MLQ app.
The platform combines fundamentals, alternative data, and ML-based insights for smarter trading and investing.
You can sign up for a free account here or learn more about the platform here.