

2023 was undoubtedly a breakout year for large language models (LLMs).
As we saw proprietary, closed source models like GPT-4 set new standards for AI and take LLMs into the mainstream, open source LLMs saw an equally impressive rise in model size and capabilities.
From major corporations like Meta releasing open source LLMs with tens of billions of parameters, to research labs releasing models trained for less that $600, the pace of development for language models shows no sign of slowing down.
In this guide, we'll look at the top open source large language models (LLMs) to watch, including their key use cases, model weights, and more.
Open Source LLMs
The models we'll look at include:
| Model Name | Parameter Range |
|---|---|
| Llama 2 | 7B - 70B |
| Mistral | 7B - 12.9B |
| Falcon | 1.3B - 180B |
| Dolly 2.0 | 12B |
| MPT | 7B - 30B |
| BLOOM | 176B |
| OpenLLaMA | 3B - 13B |
| Guanaco | 65B |
| CausalLM | Up to 70B |
| Stanford Alpaca | 7B |
| OpenChatKit | 20B |
| GPT4All | 3B - 13B |
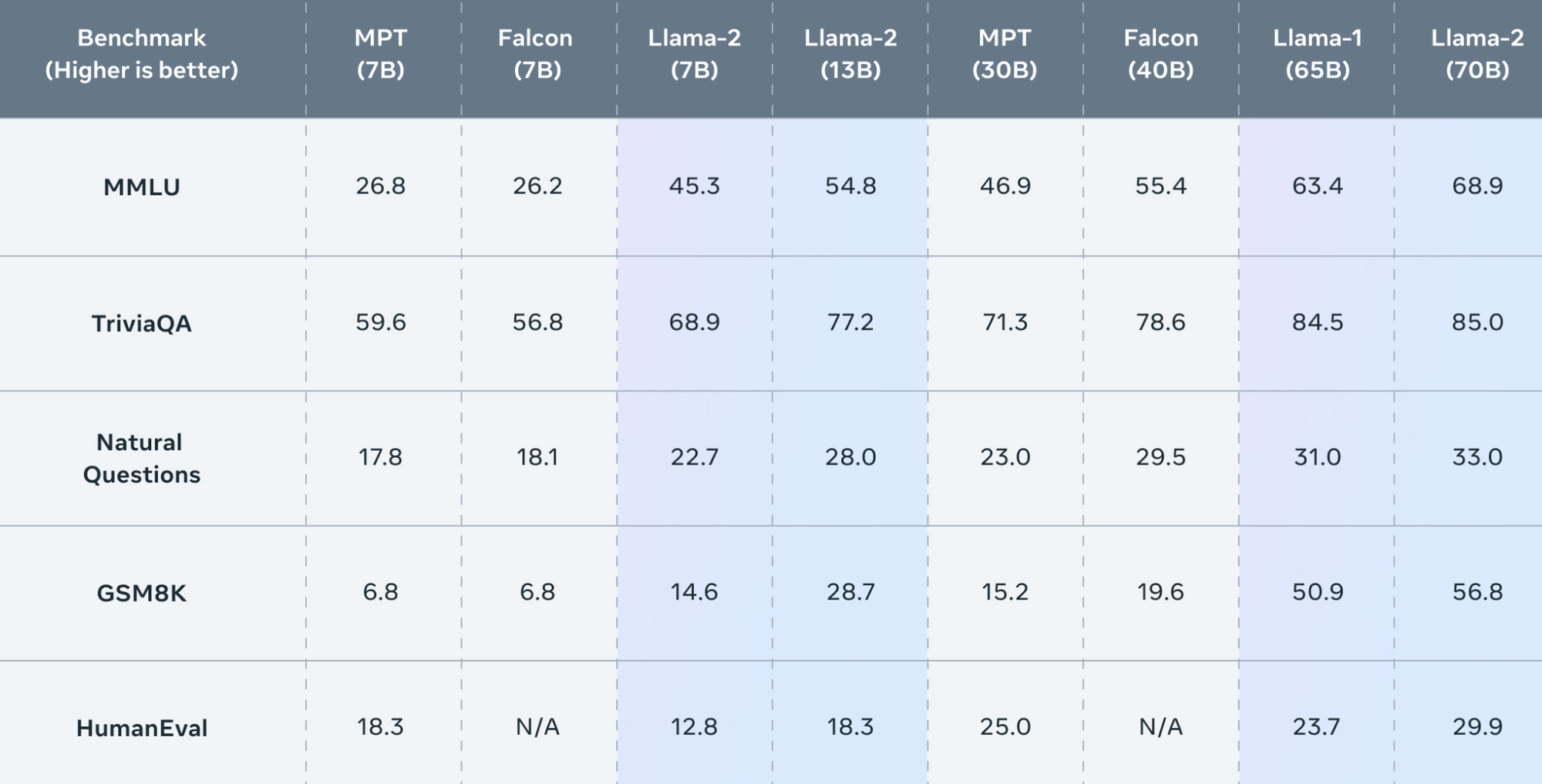
Llama 2
Developed by Meta, Llama 2 was trained on 40% more data and has double the context window than its predecessor, Llama 1. Llama 2 was pre-trained on 2 trillion tokens and fine-tuned with over a million human-annotated instances, using both supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF).
Model highlights:
- Llama 2 model can be downloaded in various parameter sizes including 7B, 13B, and 70B.
- Llama 2 outperforms other open source LLMs in key benchmarks including reasoning, coding, proficiency, and knowledge tests.
- Llama 2 is available for free for research and commercial use.


Mistral
Mistral AI is another startup that raised the largest European seed round to date, raising a $113M seed round just 4 weeks after launching. They have since gone on to raise another $415M Series A round valuing the company at $2B at the time of writing.
In it's short company history, Mistral AI has been a prominent player in the open source LLM space, releasing two open source models to date:
- A 7B parameter model
- A 12B called Mixtral 8x7B
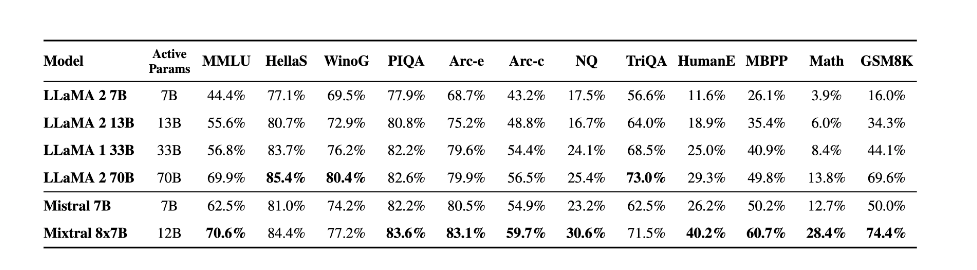
Here are a few model highlights of Mixtral 8x7B:
- Mixtral is a sparse mixture-of-experts network
- Mixtral has 46.7B total parameters but only uses 12.9B parameters per token
- It processes input and generates output for the same cost as a 12.9B model.
- The model has a 32k context window
- Shows strong performance for code generation
The best part was how they released this model with just a massive torrent file to download, which was very well received by AI developers.
magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%https://t.co/uV4WVdtpwZ%3A6969%2Fannounce&tr=http%3A%2F%https://t.co/g0m9cEUz0T%3A80%2Fannounce
— Mistral AI (@MistralAI) December 8, 2023
RELEASE a6bbd9affe0c2725c1b7410d66833e24

Falcon
Developed by the Technology Innovation Institute in Abu Dhabi, Falcon LLM is a group of models ranging that include 180B, 40B, 7.5B, and 1.3B parameter AI models.
Their largest model with 180B parameters was trained on 3.5 trillion tokens and performs well for various tasks like reasoning, coding, proficiency, and knowledge tests. This ranks closely behind OpenAI's GPT 4 and is said to be on par with Google's PaLM 2 Large, which powers Bard.

Dolly 2.0
Developed by Databricks, Dolly 2.0 is an open source instruction following LLM that is fine-tuned on a human-generated instruction dataset. The model was trained on databricks-dolly-15k (also open source), which contains 15,000 human generated prompt/response pairs for instruction tuning LLMs.
MPT
Developed by MosaicML, MPT is a family of open source LLMs offering MPT-30B and MPT-7B models. MPT-30B is a 30-billion-parameter, decoder-based transformer trained on 1 trillion tokens of English text and code. It features an 8k token context window and FlashAttention mechanism for efficiency, optimized for deployment on single GPU setups.


BLOOM
BLOOM stands BigScience Language Open-science Open-access Multilingual (catchy) and is one of the largest open source LLMs with 176 billion parameters. The model is capable of producing text in 46 natural languages and 13 programming language.

OpenLLaMA
This open-source large language model replicates Meta AI's LLaMA and is trained on 200 billion tokens with parameters ranging from 3 to 13 billion. OpenLLaMA follows the original LLaMA's architecture and training hyperparameters but uses the RedPajama dataset.
 openlm-research
openlm-researchGuanaco
Based on the LoRA fine-tuning technique, Guanaco is a 65-billion-parameter model suitable for commercial use. It introduces the QLoRA method, enabling efficient fine-tuning of large models on smaller GPUs.

CausalLM
Released on October 22, 2023, CausalLM 14B is an open-source large language model derived from Qwen 14B's initialization. It excels in benchmarks like MMLU and CEval, outperforming models under 70 billion parameters. The model is also fully compatible with Meta LLaMA 2 architecture.

Alpaca
Developed by Stanford's Center for Research on Foundation Models, Alpaca is a a fine-tuned version of the LLaMA 7B model, using 52,000 instruction-following demonstrations from OpenAI's text-davinci-003.
Alpaca is known for its efficiency, performing similarly to text-davinci-003 but smaller and cheaper to reproduce, costing under $600. The project highlights how LLMs can be incredibly asse and affordable, as the resaearchers highlihgt:
Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).

OpenChatKit
Developed by Together, LAION and Ontocord, OpenChatKit is an open-source project for creating specialized and general-purpose chatbots. It's based on the GPT-NeoXT-Chat-Base-20B model, fine-tuned with over 43 million instructions for tasks like dialogue, question answering, and summarization.
OpenChatKit includes a language model, customization tools, a retrieval system for updated responses, and a moderation model.

GPT4All
Developed by Nomic AI, GPT4All is an open-source ecosystem for training and deploying large language models on everyday hardware. Specifically, it optimizes for running 3-13 billion parameter models on standard computers and includes components for backend optimization, language bindings, API development, and a native chat application.
GPT4All supports various Transformer architectures like Falcon, LLaMA, and GPT-J. A key feature is its use of neural network quantization, allowing models to run on laptops with 4-8 GB of RAM, making powerful AI tools more accessible and customizable for a broad user base.

That's it for this list of open source LLMs to watch. We'll continue to update this as new models are released into the wild, so be sure to bookmark it or sign up for our newsletter for updates.




