

The moment all AI developers, enthusiasts, and businesses alike have been waiting...GPT 3.5 Turbo fine tuning has arrived.
The idea of fine tuning is that you can improve model performance for specific use cases by providing training examples containing ideal model outputs you'd like to see. As OpenAI highlights:
Early tests have shown a fine-tuned version of GPT-3.5 Turbo can match, or even outperform, base GPT-4-level capabilities on certain narrow tasks.
In this guide, we'll discuss exactly what fine tuning is, use cases & examples of fine-tuning, and how to get started with your own fine tuning project.
- What is GPT 3.5 Turbo fine tuning?
- How does fine tuning work in the context of GPT 3.5 Turbo
- Use cases of GPT 3.5 Turbo fine tuning
- How to get started with GPT 3.5 Turbo fine tuning
What is GPT 3.5 Turbo fine tuning?
Fine tuning refers the process of refining a pre-trained large language model (i.e. GPT 3.5 Turbo) with examples specific to your use case. As you probably know, the GPT models were trained on essentially the entire internet worth of text data.
While these models are undoubtedly impressive on their own, fine tuning allows you to tailor the models and produce more reliable outputs for certain tasks.
Fine tuning is the process of training a pre-trained model on a new, smaller dataset, that is tailored to a specific task or to exhibit certain behaviours.
For example, brands may want to fine tune GPT 3.5 Turbo to match a consistent tone of voice, provide more reliable outputs with specific formatting, and so on.
One of the most successful applications of fine-tuning comes from OpenAI themselves (of course) with their Function Calling capability. In this case, they've fine tuned the gpt-3.5-turbo-0613 and gpt-4-0613 models to intelligently choose to output a JSON object containing arguments to call functions.
In summary, OpenAI highlights that fine tuning provides the following benefits:
- Higher quality results than prompting
- Ability to train on more examples than can fit in a prompt
- Token savings due to shorter prompts
- Lower latency requests
 Peter Foy
Peter Foy
Examples & Use Cases of GPT 3.5 Turbo Fine Tuning
As mentioned, fine tuning can improve model performance for specific tasks, here are few practical examples of fine tuning:
Improved steerability
Steerability refers to the ability to guide a model's response toward a specific direction or outcome using instructions.
Example: a chatbot tutor fine-tuned for steerability can adjust its answers to fit a grade 5 student's level rather than providing complex, college-level explanations.
Reliable output formatting
Ensures consistent and desired structure in the model's responses.
Example: A software development company could fine-tune GPT-3.5 Turbo with formatted code datasets, ensuring that when users write in Python or JavaScript, the model suggests syntax-appropriate completions.
Custom tone
Adjusting the model to reflect a specific brand or voice.
Example: The brand Old Spice fine-tunes GPT-3.5 Turbo to develop a chatbot that delivers quirky and humorous responses, mirroring their distinctive brand voice.
Cost-effective outputs
Tailoring the model for concise outputs to save on API costs.
Example: A media company fine-tunes GPT-3.5 Turbo to provide concise news summaries, ensuring faster API calls and reduced costs for their high-traffic mobile app.
As you can see, the use cases of fine tuning are wide ranging and apply to nearly any businesses that are serious about integrating GPT models into their apps or business.
Pricing for GPT-3.5 Turbo Fine-Tuning
The costs structure for fine tuning works as follows:
- Training Costs: $0.008 per 1K Tokens
- Usage Costs: Input at $0.012 per 1K Tokens and Output at $0.016 per 1K Tokens
For example, if you fine-tune GPT-3.5 Turbo with a training file of 100,000 tokens spanning 3 epochs, you're looking at an approximate training cost of $2.40.
Step by Step: How to Fine Tune GPT-3.5 Turbo
Now that we know what fine tuning is and have a few practical examples, here's a breakdown of how to get started with GPT-3.5 Turbo fine tuning:
- Prepare your data
- Upload files
- Create a fine-tuning job
- Deploy the fine tuned model
Step 1: Prepare your data
Unlike previous GPT fine tuning, with 3.5 Turbo we need to structure the training in conversational flow, guiding the model's behavior. To do so, we use GPT 3.5 Turbo's messages input:
Chat models take a list of messages as input and return a model-generated message as output. Although the chat format is designed to make multi-turn conversations easy, it’s just as useful for single-turn tasks without any conversation.
To recap, here's how each message role works:
- The
systemmessage helps set the behavior of the assistant. - The
usermessages provide requests for theassistantto respond to. assistantmessages store previous chat responses, and can also be used to you to give examples of desired behavior.
As you can see, for the purpose of fine-tuning, the goal will be to provide examples of user input and desired assitant responses. For example, OpenAI provides the following example to fine tuning an assistant that occasionally misspells words (very useful, I know):
{
"messages": [
{ "role": "system", "content": "You are an assistant that occasionally misspells words" },
{ "role": "user", "content": "Tell me a story." },
{ "role": "assistant", "content": "One day a student went to schoool." }
]
}
Here's another example from their fine tuning docs to fine tune an assistant that is both factual and sarcastic:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
In the example above, we can see this has three training examples (i.e. conversations) that could be used for a training set. Now, the question is...
How many training examples should you provide for GPT-3.5-turbo fine tuning?
OpenAI suggests a minimum of 10 examples for training, although as they highlight:
We typically see clear improvements from fine-tuning on 50 to 100 training examples with gpt-3.5-turbo but the right number varies greatly based on the exact use case.
In my experience with previous fine tuning, I would typically use at least 100 examples to get the best results, and sometime upwards of 10,000+ training examples.
Alright after we've got our training examples we need to save it in a JSONL file. For this demo example, I'll just test the sarcastic/factual assistant and use ChatGPT create 7 more similar examples to get to the minimum of 10.
Before creating the fine tuning job, we can also double check our formatting is correct with the data formatting script here.
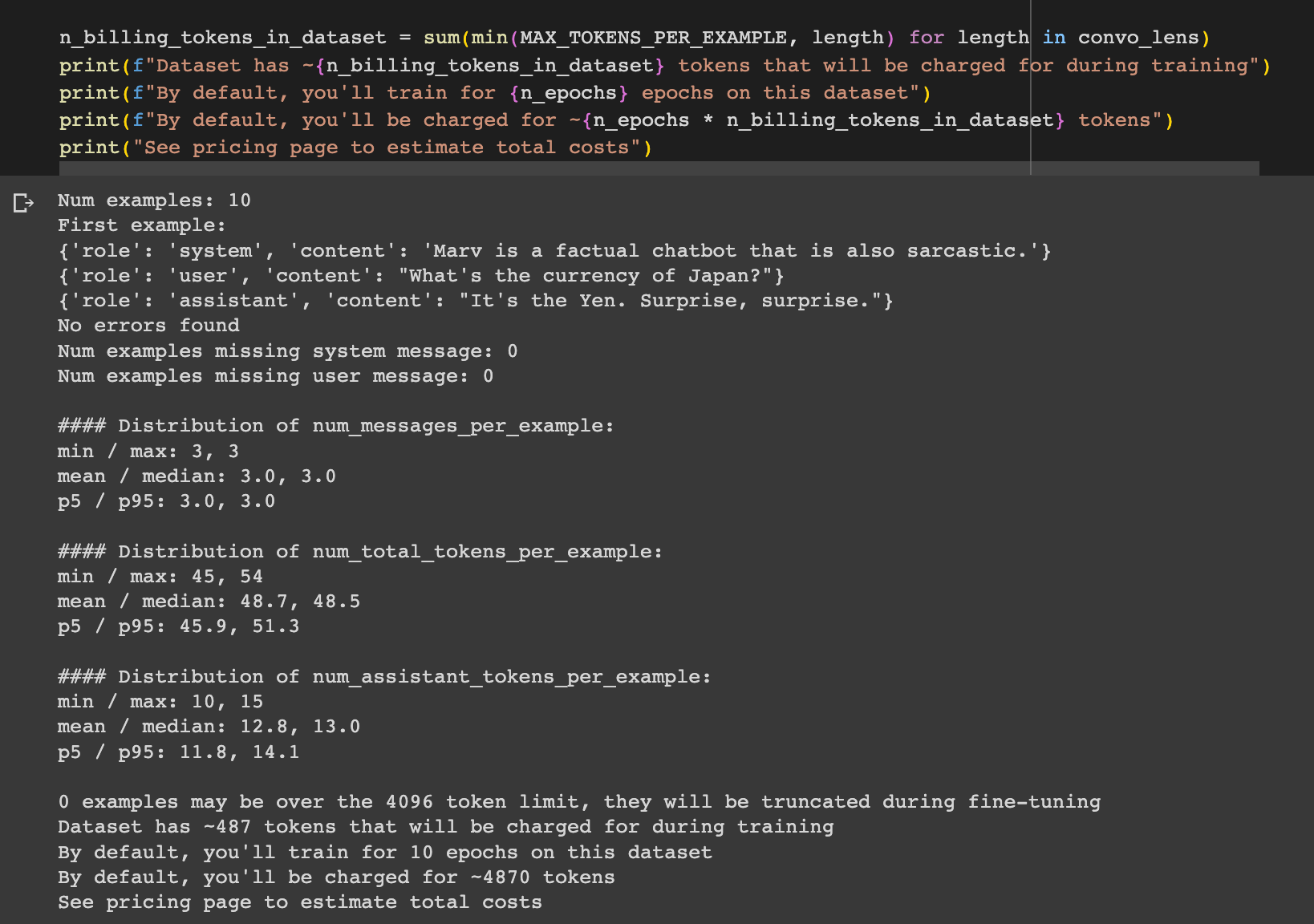
Alright looking good, now onto the next step, uploading our JSONL file.
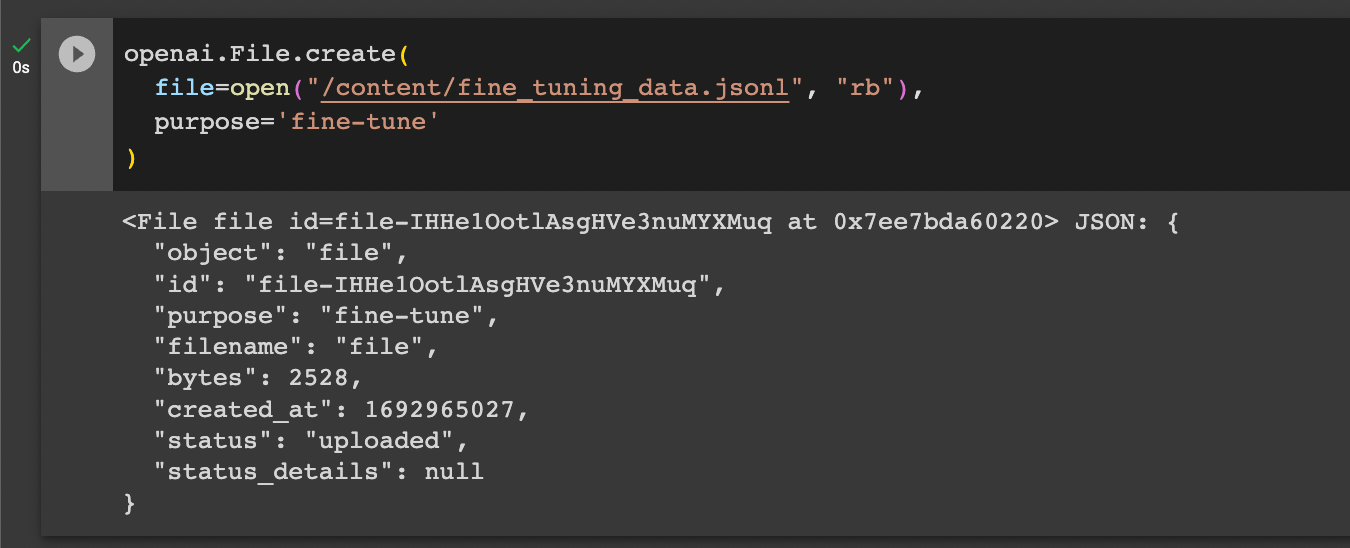
Step 2: Upload Files
Next we need to upload our structured data using OpenAI's API as follows, note you'll just need to set your OpenAI API key before running this:
openai.File.create(
file=open("/content/fine_tuning_data.jsonl", "rb"),
purpose='fine-tune'
)
Step 3: Create a Fine-Tuning Job
After uploading our traning data, let's now create a fine tuning job as follows, you'll just need to update file-abc123 with your file ID generated in the previous step:
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")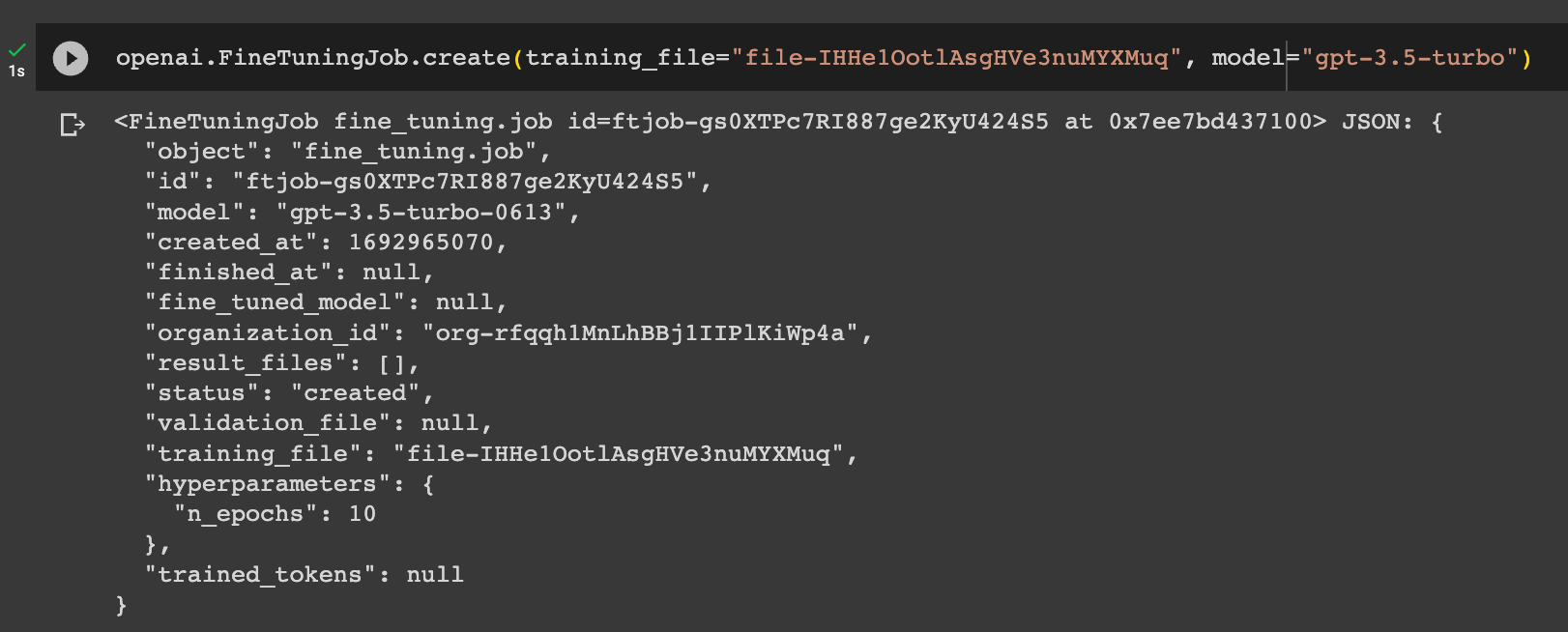
Now we can see the status is created, and we'll just need to wait a few minutes to complete, we can also check the status as follows:
openai.FineTuningJob.retrieve("ft-abc123")
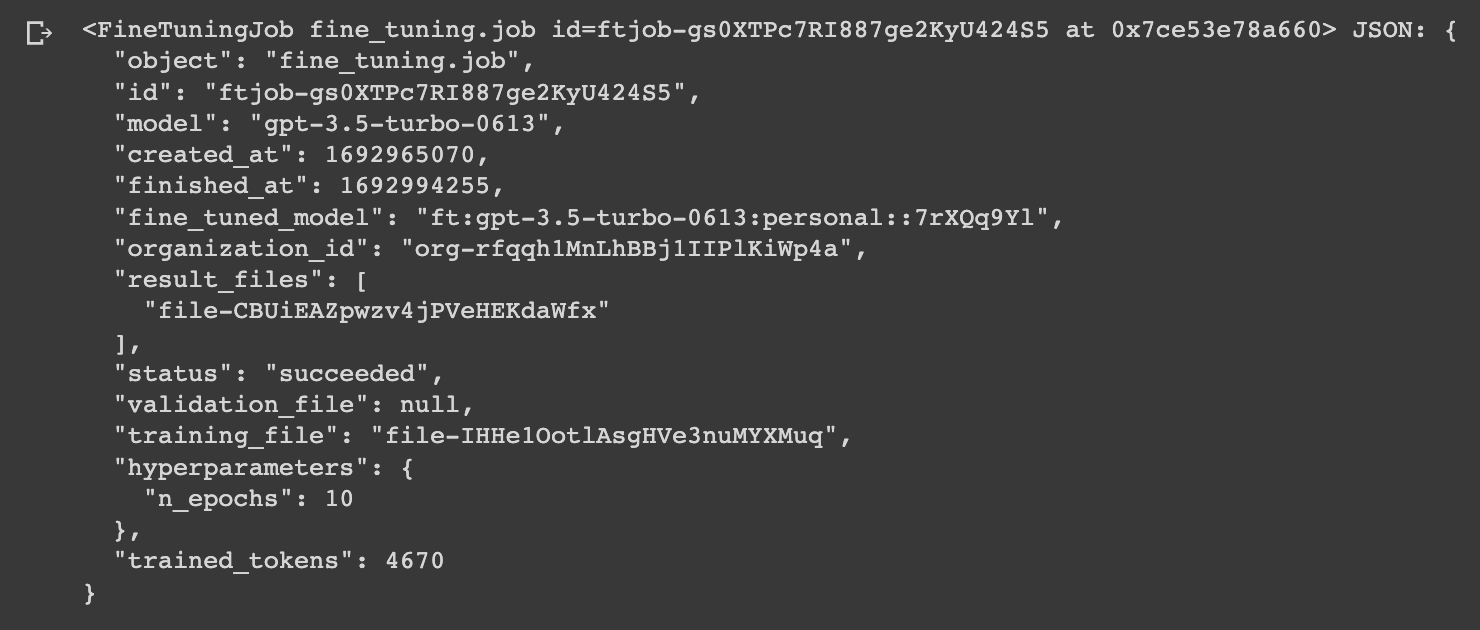
Step 4: Using the Fine-Tuned Model
Now that the fine tuning job is complete, let's go and test it out as follows, note you'll just need to update this with your OpenAI organization number & the custom ID of your fine tuning job ft:gpt-3.5-turbo:my-org:custom_suffix:id:
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."},
{"role": "user", "content": "What's the capital of France?"}
]
)
print(completion.choices[0].message)
Now, it's tough to say whether fine tuning or the system message led to this response given that we only provided 10 examples, so a more in-depth experiment will be needed, which we'll cover in future guides.
Summary: GPT 3.5 Turbo Fine Tuning
While fine tuning is a great tool in the prompt engineers toolkit, it's important to note that it usually shouldn't always be the first option when trying to improve model performance. Instead, I would recommend starting with some basic prompt engineering (i.e. providing several examples via few shot learning) so you have a baseline, and then experiment with fine tuning to see how notable the improvements are.
That said, given that fine tuning can lead to 3.5 turbo performing like GPT-4, the cost savings of fine-tuning can certainly add up if you're running a larger scale application.
In this guide, we just scratched the surface of what you can do with fine tuning, so in the future guides we'll provide more real-world examples that demonstrate how we can take advantage of this new capability.




