
Large language models (LLMs) like the GPT models are based on the Transformer architecture.
Introduced in the famous Attention is All You Need paper by Google researchers in 2017, the Transformer architecture is designed to process and generate human-like text for a wide range of tasks, from machine translation to general-purpose text generation.
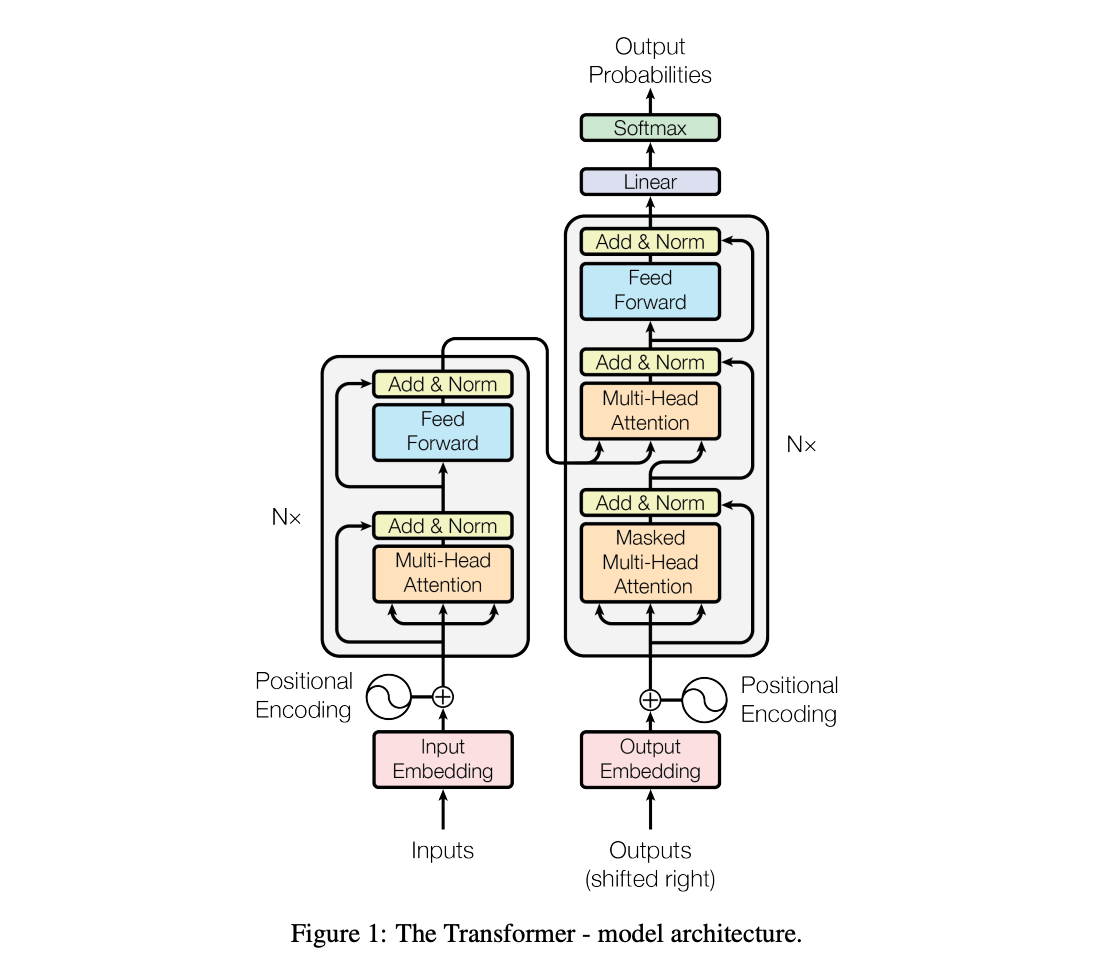
Transformer Architecture
At their core, the Transformer architecture uses what's called self-attention mechanism to process input data.
We propose a new simple network architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely.
Unlike previous deep learning models for natural language processing, such as RNNs and LSTMS which process data sequentially, Transformers are able to handle input data in parallel. This not only improves the model efficiency, but also increases it's capability in understanding context within language.
Key components of the Transformer:
- Embedding Layer: This converts input tokens (aka words) into vectors, which are numerical representations of the words along with semantic meaning and context of the text.
- Positional Encoding: This step adds information about the position of each token in the sequence to its embedding. The purpose of this is to compensate for the lack of sequential processing in the Transformer.
- Encoder and Decoder: The encoder processes input text and extracts context information, while the decoder generates coherent responses by predicting the next words in a sequence.
- Self-Attention Mechanism: Self-attention allows the model to weigh the importance of different words in the input sequence. This enables it to understand context and relationships between words across the entire input sequence, which is essential for natural language where the meaning of a word can change based on its context within a sentence.
- Feedforward neural networks: Both the encoder and decoder have feedforward neural networks which are responsible for applying additional transformations to the data processed by the self-attention mechanism. This enables them to capture even more nuanced features and context of natural language.
- Layer Normalization & Residual Connections: Finally, these are techniques used within the model blocks to increase the training stability, avoid the vanishing gradient problem, and facilitate the training of deeper neural networks.
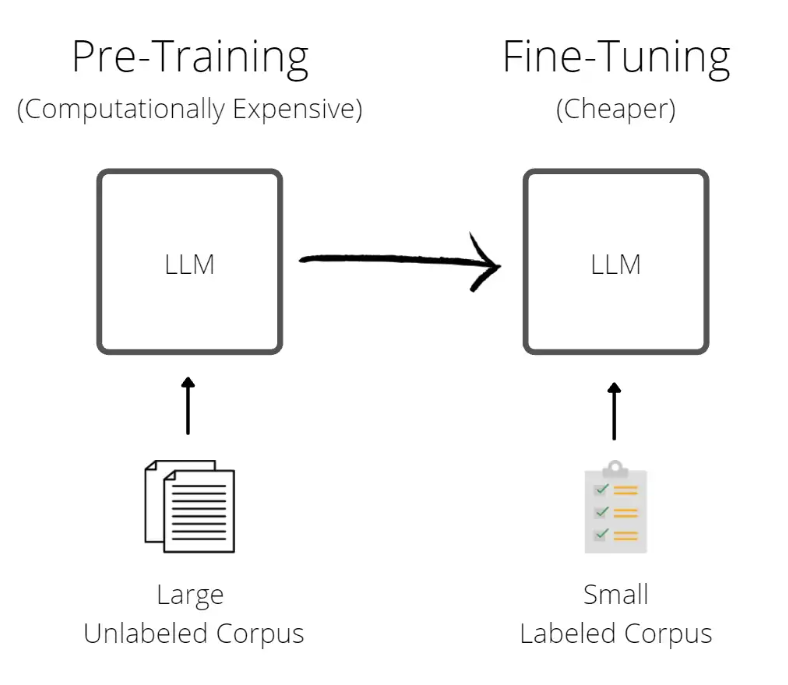
Pre-Training & Fine Tuning LLMs
The process of training an LLM typically undergoes two main phases:
- Pre-training: This phase involves training the model on a huge amount of text using various unsupervised learning techniques. During pre-training, the model focuses on tasks like predicting the next word and enables the model to gain a general understanding of language and context.
- Fine tuning: After pre-training, the model is then typically fine tuned on a smaller, task-specific dataset. This step involves adjusting the models weights to perform well on specific tasks, such as answering questions, classification, and so on. This step adapts its learned representations during pre-training to perform well on specific tasks, without starting the training prcess from scratch.
In summary, LLMs are based on the Transformer architecture and their general-purpose versatility for generating coherent text have undoubtedly revolutionized the field of AI.




