

When you're working with large language models (LLMs), there are two key concepts that you'll often come across: tokens and context windows.
Tokens and context windows are fundamental for understanding how transformer-based LLMs process and generate text, so let's dive into each a bit more detail.
What are Tokens?
Tokens are the basic building blocks for LLMs and represent the smallest unit of text the model can understand and process.
A token can include whole words, parts or words, or even a character or punctuation marks, depending on how the text is broken down (i.e. tokenized).
Why do tokens matter?
By converting text into tokens, an LLM can process and generate text in a more structured way, enabling it to learn patterns and relationships between the tokens.
The process of tokenizing words allows the model to understand syntax (i.e. the structure of sentences) and semantics (i.e. the true meaning conveyed by words & sentences).
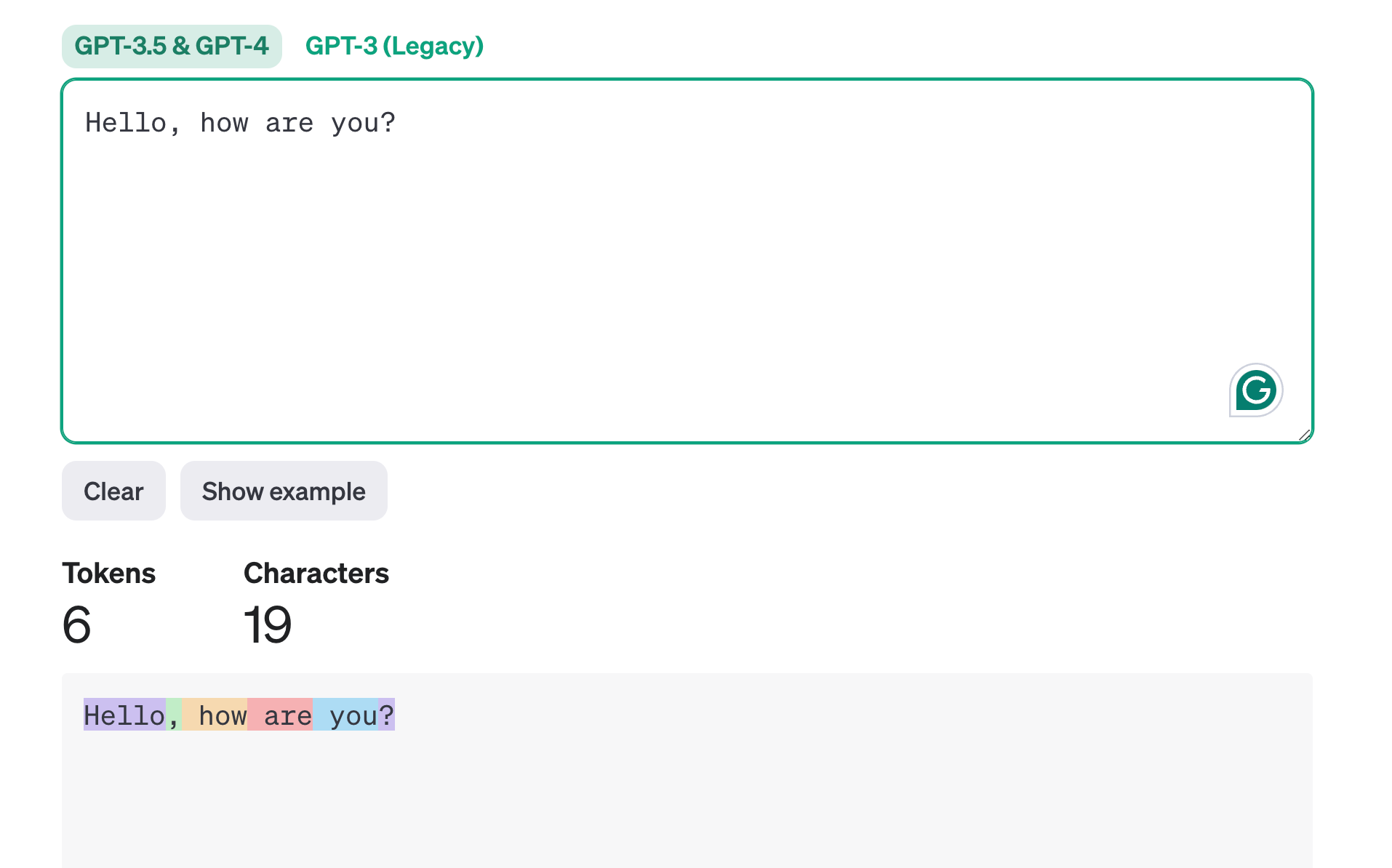
OpenAI Tokenizer
A useful tool for familiarizing yourself with tokens OpenAI's tokenizer tool:
You can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text.
Tokenization techniques
Tokenization is the process of converting raw text into a sequence of tokens.
In simple terms, you can think of tokenization as breaking down a larger piece of text into smaller, more manageable pieces that a model can understand and work with.
The two main tokenization techniques include:
Word-based tokenization
This splits text into individual words. It is a more straightforward technique, but can lead to a large vocabulary size.
Subword tokenization
Instead of splitting based on words, this technique splits text into subwords or symbols. These subwords can be common parts of words, endings like "-ing," or even single letters.
This is a more common approach used by models like GPT as it reduces the vocabulary size and helps in handling out-of-vocabulary words. In other words, by breaking down words into smaller pieces, it reduces the total number of subwords the model needs to remember.
Let's look at a hypothetical example with the word "inexplicable" and let's say the model hasn't encountered this word before.
With subword tokenization, the model might break down the word "inexplicable" into sub-parts like "in-explic-able". Here's why this is helpful to the model:
- "in-" is a common prefix meaning not or into,
- "explic" could be seen as a root related to explaining or understanding (think of "explicit" or "explicate"),
- "-able" is a common suffix meaning capable of or susceptible to.
Now, even though the model hadn't seen the word "inexplicable" before in this example, it can now understand the meaning by analyzing these known parts.
Several popular subword tokenization algorithms include Byte-Pair Encoding (BPE), WordPiece, and SentencePiece.
How many tokens are in a word?
As mentioned, with subword tokenization words aren't always split into tokens exactly where they start or end, and they can include trailing spaces and sub-words.
As a general rule of thumb, however, here's how OpenAI suggests to count tokens:
- 1 token ~= 4 chars in English
- 1 token ~= ¾ words
- 100 tokens ~= 75 words
Now that we know what tokens are, let's move onto another foundational concept when working with LLMs: context windows.
What are context windows?
The context window of an LLM refers to the amount of text in tokens that the model can consider in one go when making predictions or generating text.
The context window refers to the amount of tokens that can be fed into the model at once in order to understand or generate a piece of text. In other words, this "window" of text is the amount of tokens the model considers when predicting the next word in a sentence.
Why do context windows matter?
The size of a models context window determines how much information the model can consider at once when making predictions. The larger the context window, the more text the model can consider, which often leads to a better understanding of context and more coherent responses.
That said, there is a tradeoff between context window and computational resources, as large windows require more memory and processing power.
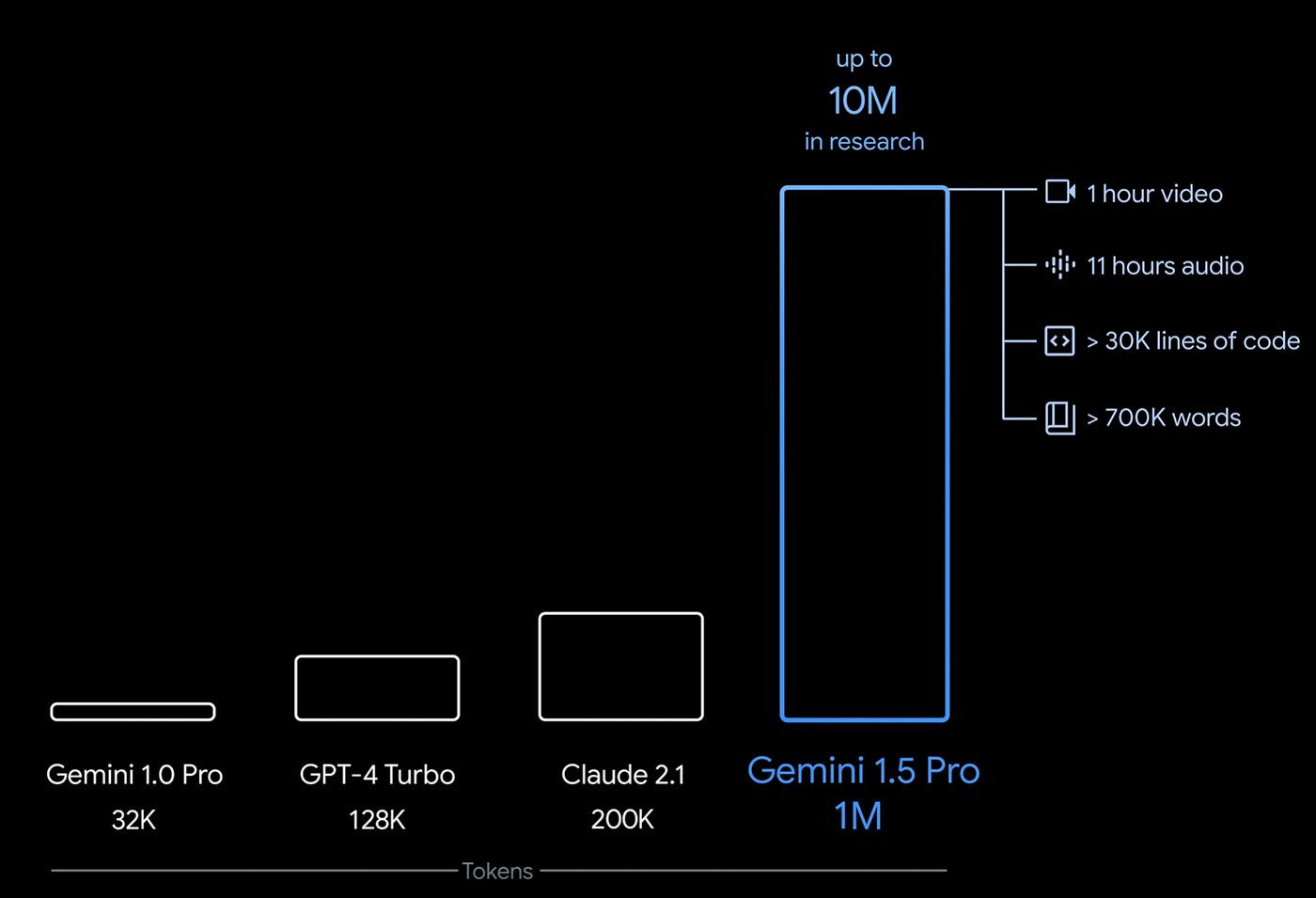
Example: Context Windows of the Top LLMs
Here's an example of how context windows currently compare against several of the top LLMs, although keep in mind these are constantly changing.
Summary: Tokens & Context Windows
Together, tokens and context windows enable large language models models to effectively process information and generate text.
Here's how they work together:
- Tokens allow the model to break down words into smaller chunks of text that can be analyzed in order to learn relationships and patterns between the smaller units of text.
- Context windows give the model a "scope of understanding", meaning they enable it to consider the full context of the text (assuming it fits within window size) when processing, making predictions, and generating text.
For example, a model is able to understand the difference between a "bank" as a financial institution vs. a "bank" as the side of the river by consider then tokens around these words within the context window.
By combining these two key concepts, Transformer-based models are able to understand the many nuances of natural language.




