
In this article we'll look at how we can use TensorFlow to analyze and predict text using natural language processing (NLP).
Whereas images often come in regular shaped tensors of pixel values, text data is typically messier and more difficult to deal with. Below we'll discuss how to handle the inherent complexity that comes with language including dealing with short vs. long sentences and processing individual characters, words, and sentences.
Firstly, this involves processing text into numbers that we can use for calculating the weights and biases that we can feed into a neural network. Then, we'll look at more advanced topics such as sentence padding and vocabulary tokens that are key to natural language processing.
This article is based on notes from this course on Natural Language Processing with TensorFlow and is organized as follows:
- Word-Based Encodings
- Text to Sequence
- Sequence Padding
- Word Embeddings
- Sequence Models for Natural Language Processing
- Sequence Models for Text Generation
Stay up to date with AI
1. Word-Based Encodings
As mentioned in our previous article on convolutional neural networks, computer vision problems use convolutions to identify features in images and use them for classification.
In the case of natural language processing, we're focused on building a classifier based on text models. First off, we'll look at sentiment in text and then learn how to build models that can classify new text based on the training data it has seen.
In order to encode text to numbers, we could take character encodings such as the ASCII values, although the issue is that the semantics of the word aren't encoded in the letters. For example, the words "silent" and "listen" have the exact same characters but a completely different meaning. That said, training a neural network with just characters can be a challenging task.
Instead, we can give words a value and use these to train the network. The value of each word doesn't exactly matter, it just needs to be the same value for the same word each time. For example, we can encode the sentence "I love my dog" as 001, 002, 003, 004. If we have the sentence "I love my cat" we can create a new token for "cat", so it could be encoded as 001, 002, 003, 005.
This is a starting point for training a neural network, although fortunately TensorFlow and Keras have already done this word-based encoding for us and made it available through several APIs, one of which is called Tokenizer.
The Tokenizer generates the dictionary of word encodings and creates vectors from sentences. Here's how we can encode the two sentences we just saw with the Tokenizer API:
- We first put the sentences into an array
- We then create an instance of the
Tokenizerand set the parameternum_wordsto 100. This parameter takes the top 100 words by volume and encodes those, although we only have 5 in this basic example. - The
fit_on_textsmethod ontokenizertakes in the data and encodes it - The
tokenizerprovides aword_indexproperty that returns a dictionary with key-value pairs where the key is the word and the value is the to
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.preprocessing.text import Tokenizersentences = [
'I love my dog',
'I love my cat'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
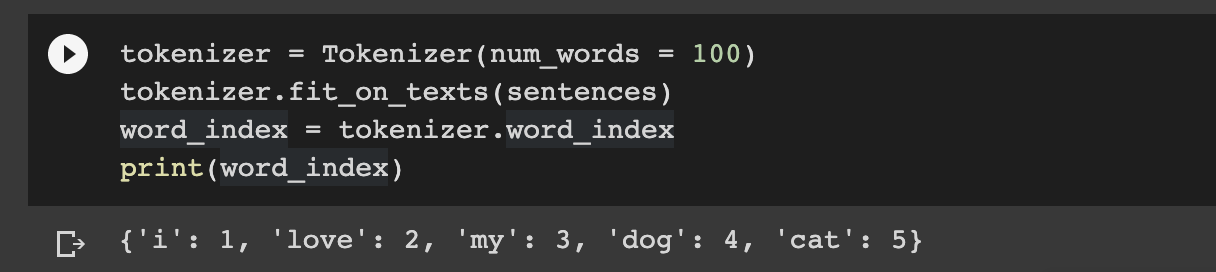
You'll notice that the "I" has been stripped of its capitalization and if we add punctuation this will also be stripped away.
2. Text to Sequence
We just looked at how to tokenize words and sentences in order to build up a dictionary of all the words that make up a corpus. The next step is to turn sentences into lists of values based on these tokens.
We'll then also likely need to manipulate these lists, for example making every sentence the same length, in order to use them for training a neural network. We saw the same concept in our guide to CNNs with TensorFlow—when images were sized differently, we needed to resize them to fit the network.
Once again, TensorFlow has APIs to deal with resizing for text data. For example, we can update our code as follows:
- Below we've added one sentence that is longer
- We also call on the tokenizer to get
text_to_sequences, which will turn our sentences into a set of sequences
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(sentences)
print(word_index)
print(sequences)
At the top we have our new dictionary with new tokens for new words. Below that, we have a list of sentences that have been encoded into integer lists with tokens instead of words.
Keep in mind that text_to_sequences can take any set of sentences, so it can encode them based on the word set that we passed to fit_on_texts. This means that if we train a neural network on a corpus of text and a word index is generated, in order to perform inference with the trained model we'll have to encode the text we want to infer on with the same word index, otherwise it will be meaningless.
In other words, we need a lot of training data in order to get a broad vocabulary or we could end up with lists of encoded sentences that don't make any sense.
In many cases, instead of just ignoring unseen words it's a good idea to use a special value in when one is encountered. We can do this using a property on the tokenizer, oov_token, which stands for "out of vocabulary":
tokenizer = Tokenizer(num_words = 100, oov_token="<00V>")
3. Sequence Padding
As mentioned, just like how image data that needs to be in uniform size, text data has similar requirements of uniformity, and one way we can do this is with sequence padding.
In order to use padding functions from TensorFlow we need to import the following:
from tensorflow.keras.preprocessing.sequence import pad_sequences
We can then pass our sequences to pad_sequences as follows:
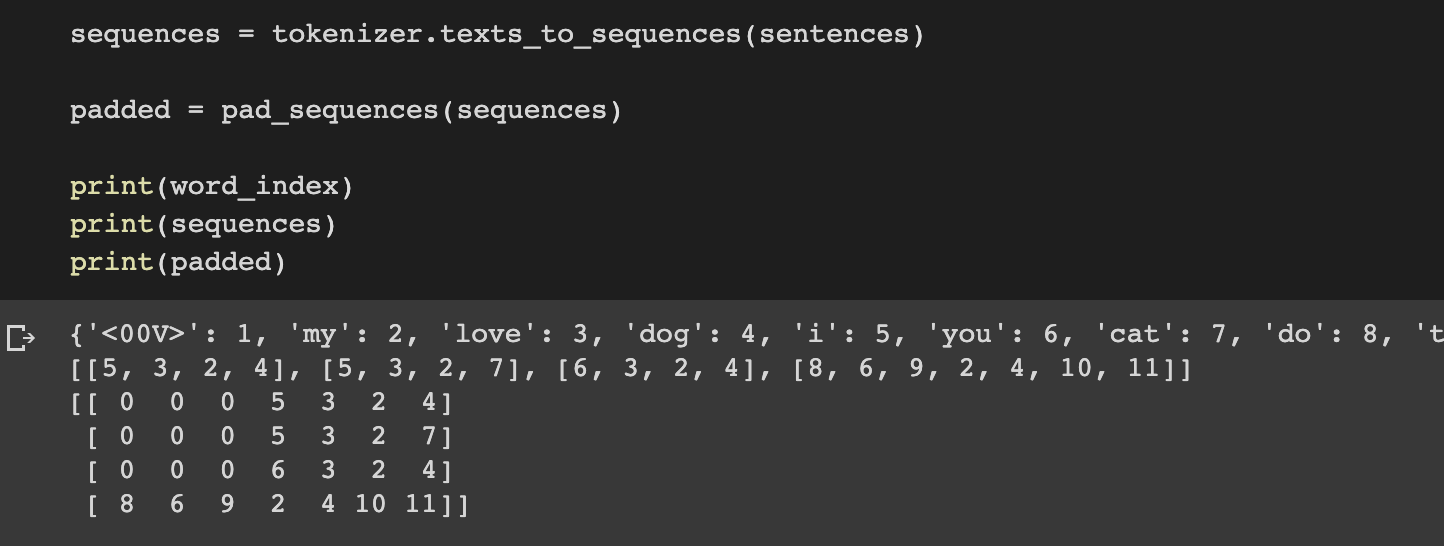
We can now see the list of sentences has been padded out into a matrix and that each row in the matrix has the same length. It does this by putting the required number of 0's before the sentence.
If we want to padding to occur after the sentence we can add padding='post'. If we want to set a maximum padding length we can use maxlen=5, for example.
4. Word Embeddings
Let's now look at how to use TensorFlow and Keras to implement word embeddings, which is one of the most important ideas in natural language processing.
If we have a corpus of 10,000 words, for example, the basic idea of word embeddings is to represent these words in a better way than just using the numbers 1-10,000. As MachineLearningMastery describes:
Word embeddings are a type of word representation that allows words with similar meaning to have a similar representation.
Similar to how we extract features from images using convolutions, the process of extracting sentiment from words can be done through embedding.
The idea of embedding is that closely related words will be clustered together as vectors in a multi-dimensional space.
IMDB Dataset
Another one of the datasets included in TensorFlow is the IMDB reviews dataset, which contains 50,000 movie reviews that are categorized as positive or negative.
We can import the dataset as follows:
import tensorflow_datasets as tfds
imdb, info = tfds.load("imdb_reviews", with_info=True, as_supervised=True)The data is split into 25,000 images for training and 25,000 for testing, which we can split out like this:
train_data, test_data = imdb['train'], imdb['test']Each of these are iterables with 25,000 sentences and labels as tensors, so we can iterate over the training and testing data and extract the sentences and labels with for loops as follows:
import numpy as np
training_sentences = []
training_labels = []
testing_sentences = []
testing_labels = []
for s, l in train_data:
training_sentences.append(str(s.numpy()))
training_labels.append(l.numpy())
for s, l in test_data:
testing_sentences.append(str(s.numpy()))
testing_labels.append(l.numpy())When training the labels are expected to be NumPy arrays so we can convert the list of labels we just created as follows:
training_labels_final = np.array(training_labels)
testing_labels_final = np.array(testing_labels)Next we can tokenize and pad the sentences with the following hyperparameters:
vocab_size = 10000
embedding_dim = 16
max_length = 120
trunc_type='post'
oov_tok = "<OOV>"
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer(num_words = vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(training_sentences)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(training_sentences)
padded = pad_sequences(sequences,maxlen=max_length, truncating=trunc_type)
testing_sequences = tokenizer.texts_to_sequences(testing_sentences)
testing_padded = pad_sequences(testing_sequences,maxlen=max_length)Now we can define our neural network as a Sequential model with the first layer set as an Embedding layer. The result of the embedding will be a 2D array with the length of the sentence and embedding dimension as the size, so we need to flatten it with a Flatten layer. We then feed that into two Dense layers for classification:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, input_length=max_length),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(6, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
We can compile the model and print out the summary with the code below:
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
Training can be done by passing padded and training_labels_final as our training set, specifying the number of epochs, and passing the testing_padded and testing_labels_final as our test set:
num_epochs = 10
model.fit(padded, training_labels_final, epochs=num_epochs, validation_data=(testing_padded, testing_labels_final))5. Sequence Models for Natural Language Processing
Let's now look at how to implement sequence models such as recurrent neural networks (RNNs) for natural language processing in TensorFlow.
Sequence models are important in NLP since the relative order of words provide an extra layer of meaning in sentences. One reason that sequence models such as RNNs and LSTMs are useful for NLP is that the context is preserved from timestamp to timestamp.
We won't cover RNNs in detail here, but here's an overview from our Introduction to RNNs and LSTMs:
Recurrent neural networks are designed to learn from sequences of data by passing the hidden state from one step in the sequence, to the next step, and combining this with the input.
You can learn more about RNNs from Andrew Ng's course on Sequence Models here.
LSTMs, or Long Short-Term Memory Networks, are an update to RNNs which, in addition to the context being passed from RNNs, pass another pipeline of context called the cell state.
The cell state helps keep context from earlier tokens so that they can be accessed later on. Cell states can also be bidirectional, which means that later contexts can impact earlier ones.
You can also learn more about LSTMs from Andrew Ng's course on Sequence Models. Below is an example of a model that uses an LSTM in the second layer:
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])6. Sequences Models for Text Generation
Now that we've reviewed NLP for text classification, let's look at how we can use TensorFlow to predict text, which leads us to natural language generation.
Text prediction is similar to what we've already discussed—we take a body of text, extract the full vocabulary from it, and then create datasets where we make the phrase the $x$'s and next word we're predicting to be the $y$'s.
Given enough words in a corpus, a neural network can predict and generate relatively sophisticated text. For example, the largest language generation model is currently GPT-3, which was trained on 175 billion parameters.
We won't cover the code for text generation in this article, although you can find the full code on Github here. You can also find a tutorial from TensorFlow on generating text with an RNN here.
Summary: Natural Language Processing with TensorFlow
In this article, we introduced how to use TensorFlow and Keras for natural language processing.
The first principles of NLP include tokenization and padding in order to prepare our data for a neural network. We also discussed word embeddings and mapping words to vectors. Finally, we reviewed how sequence models such as RNN and LSTMs can be used for classification by not just looking at words in isolation, but instead accessing information previously learned in the sentence.
This is simply an introduction to natural language processing with TensorFlow—below you'll find additional resources on the topic.


