
Originally proposed in 2014 by Ian Goodfellow, the idea of generative adversarial networks GANs is to take two neural networks—a generator and a discriminator—which learn from each other in order to generate realistic samples from data.
In this article, we're going to look at using GANs to generate synthetic financial data. This guide is organized as follows:
- What are Generative Adversarial Networks?
- Applications of Synthetic Data in Finance
- TimeGAN: Adversarial Training for Synthetic Financial Data
1. What are Generative Adversarial Networks (GANs)?
As mentioned, the idea of GANs is to train two neural networks—a generator and a discriminator—and have them learn from each other in a competitive setting. The goal of the generator is to create samples that the discriminator is unable to distinguish from real training data.
This adversarial setting results in a generative model that can create completely new, synthetic samples that are representative of a target distribution. In other words, the synthetic data will have the same statistical representation as the real data.
GANs have been used for many interesting applications, including:
- Generating realistic photos & artwork
- Image-to-Image & and Image-to-Text translation
- Generating synthetic data
For our purposes, one of the most interesting applications of GANs is generating synthetic data to train machine learning algorithms.
As Stefan Jansen describes in his book on Machine Learning for Trading comparing discriminitive models vs. generative models:
Discriminative models learn how to differentiate among outcomes y, given input data X. In other words, they learn the probability of the outcome given the data: $p(y | X)$. Generative models, on the other hand, learn the joint distribution of inputs and outcome $p(y, X)$.
One of the key innovations of GANs is that the two neural networks are set up in an adversarial game. At a high-level, we can see the GAN architecture and training process from the image below:
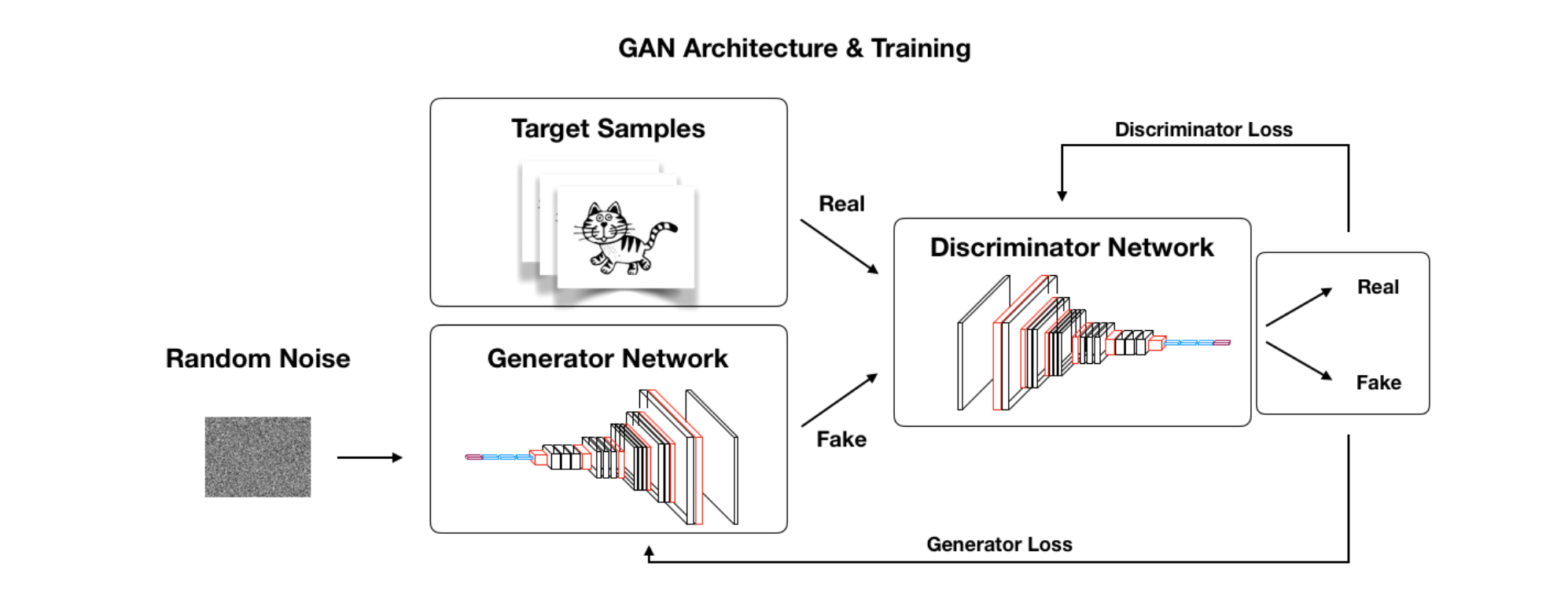
If you want to learn more about the how GANs work, check out our article on What are Generative Adversarial Networks (GANs)?
2. Applications of Synthetic Data in Finance
Time series data is very common in finance, ranging from credit card transactions to stock prices. That said, many datasets either have privacy regulations associated with them or simply lack enough quantity to be useful. In particular, synthetic data is highly valuable in a number of financial applications including:
- Machine Learning: Synthetic data can be used as both training data for machine learning algorithms and validating their effectiveness. This is useful when there's either a lack of training data or if the available data is in an unstructured format that needs to be manually labeled, for example.
- Privacy: When privacy requirements are an issue with data, synthetic data can be used as an alternative as it holds no personal information and cannot be traced back to individuals.
Let's now look at how synthetic data is used in quantitative finance.
Synthetic Data for Quantitative Finance
As discussed by Blackarbs, quantitive finance has a data problem. In particular, there are three main pain points that synthetic data addresses:
- Data Scarcity: There is only one historical time series for each financial instrument, which means there can often be a lack of data diversity. This means that not every possible market regime or events will be represented in the available data.
- Data Costs: Depending on the size of your institution's resources, market data fees can limit the ability to research and develop profitable trading strategies.
- Backtest Overfitting: One of the main challenges with backtesting quantitive trading strategies is overfitting. As this paper on mitigating overfitting from the Journal of Financial Data Science highlights:
This seemingly unavoidable pitfall has heavily impaired the application of many machine learning techniques, such as deep or reinforcement learning, to financial settings.
If you want to learn more about backtesting on synthetic data, check out Chapter 13 of Advances in Financial Machine Learning by Marcos Lopez de Prado. Now let's look at a specific type of GAN that can use used for generating synthetic financial data: TimeGAN.
3. TimeGAN: Adversarial Training for Synthetic Financial Data
In Stefan Jansen's Machine Learning for Trading book, he provides code that has been adapted from the paper called: Time-series Generative Adversarial Networks, Neural Information Processing Systems (NeurIPS), 2019. The original code author is Jinsung Yoon.
As the paper describes:
A good generative model for time-series data should preserve temporal dynamics, in the sense that new sequences respect the original relationships between variables across time.
TimeGAN Combines Unsupervised Adversarial Loss & Supervised Training
Many attempts have been made at generating time-series data, although most have results in relatively poor data quality.
Compared to other attempts at generating time-series data such as recurrent GANs, which rely on recurrent neural networks (RNNS), TimeGAN incorporates the autoregressive nature of time series data. It does this by combining unsupervised adversarial loss with supervised learning. In particular, the model rewards learning the distribution over transitions between one point in time to the next.
In other words, the authors pose a novel framework for generating synthetic time series data that combines both supervised and unsupervised training in order to account for temporal correlations. As they describe in the paper:
First, in addition to the unsupervised adversarial loss on both real and synthetic sequences, we introduce a stepwise supervised loss using the original data as supervision, thereby explicitly encouraging the model to capture the stepwise conditional distributions in the data.
The authors go on to describe the unsupervised and supervised approach:
Our approach is the first to combine the flexibility of the unsupervised GAN framework with the control afforded by supervised training in autoregressive models.
The authors test the model on several time series data sets—including stock prices—and find that the synthetic data generated is significantly higher quality than other frameworks. To do this, the TimeGAN architecture combines an adversarial network with an autoencoder.
What is an Autoencoder?
As Wikipedia describes, an autoencoder is a type of neural network that learns a particular data representation in an unsupervised manner. The goal of an autoencoder is to learn an encoding of a set of data by training the network to ignore signal "noise".
In other words, autoencoders learn nonlinear feature representations that can significantly compress complex data without losing key information. This means that it avoids losing important features in dimensionality reduction.
Overview of the TimeGAN Architecture
As mentioned, the TimeGAN architecture combines an adversarial network with an autoencoder and has the following four components:
- Autoencoder: embedding and recovery networks
- Adversarial Network: generator and discriminator networks
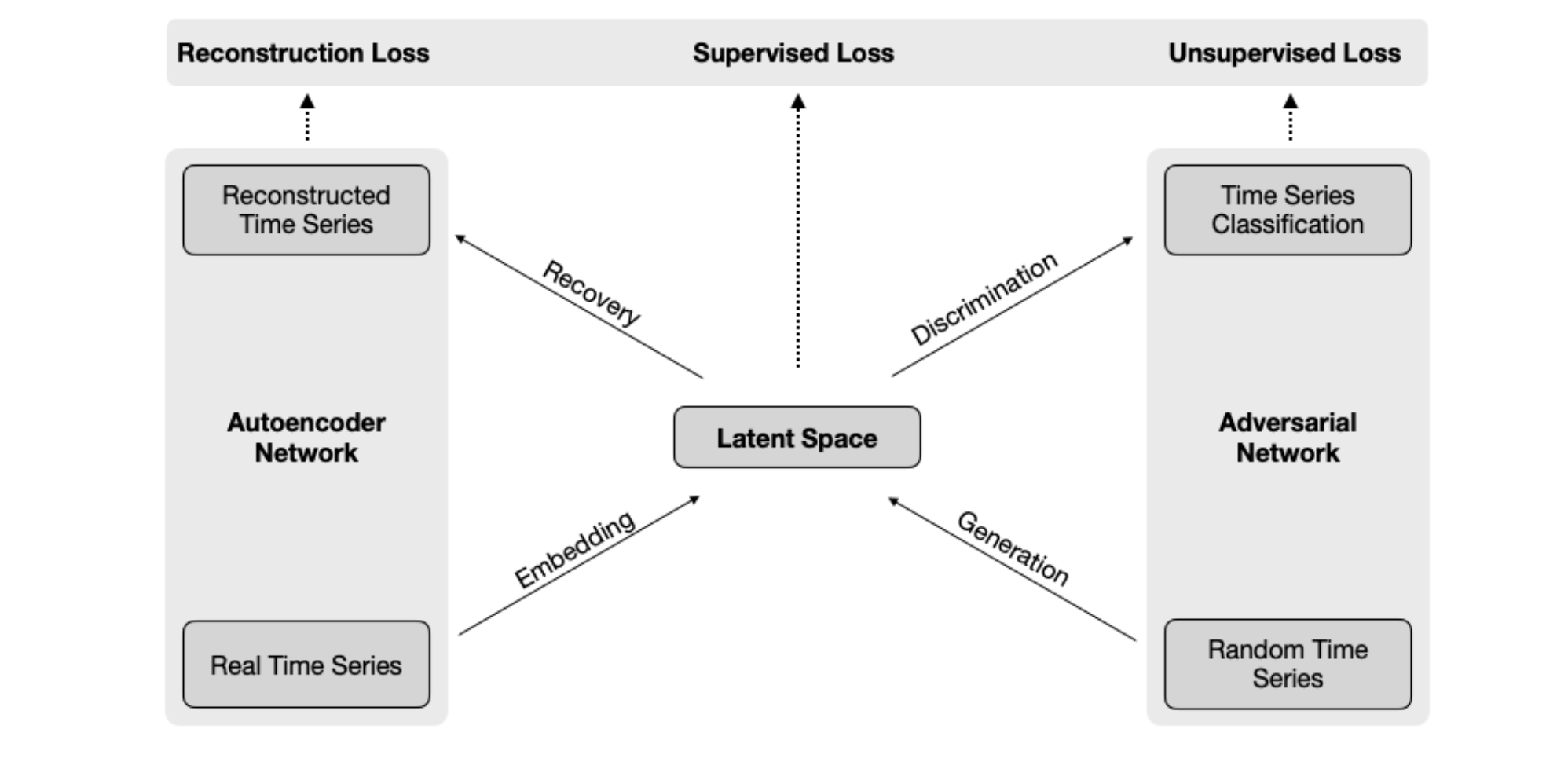
Here's a more detailed diagram from the paper:
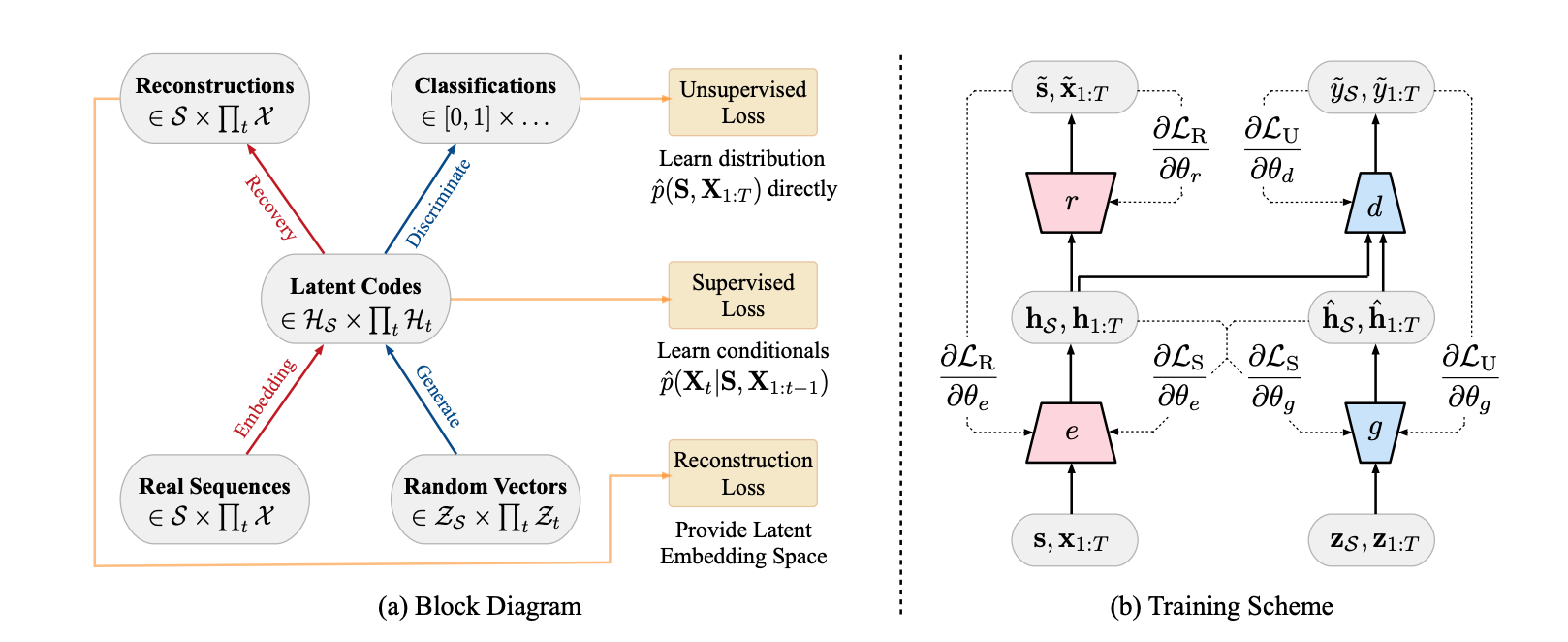
If you want to learn how to implement the TimeGAN architecture in Python check out Stefan Jansen's notebook that uses TensorFlow 2.0, which involves the following steps:
- Select and prepare real and random time series inputs
- Creating the key TimeGAN model components
- Defining loss functions and training steps used in three training phases
- Run the training loops and log the results
- Generate synthetic time series and evaluate the results
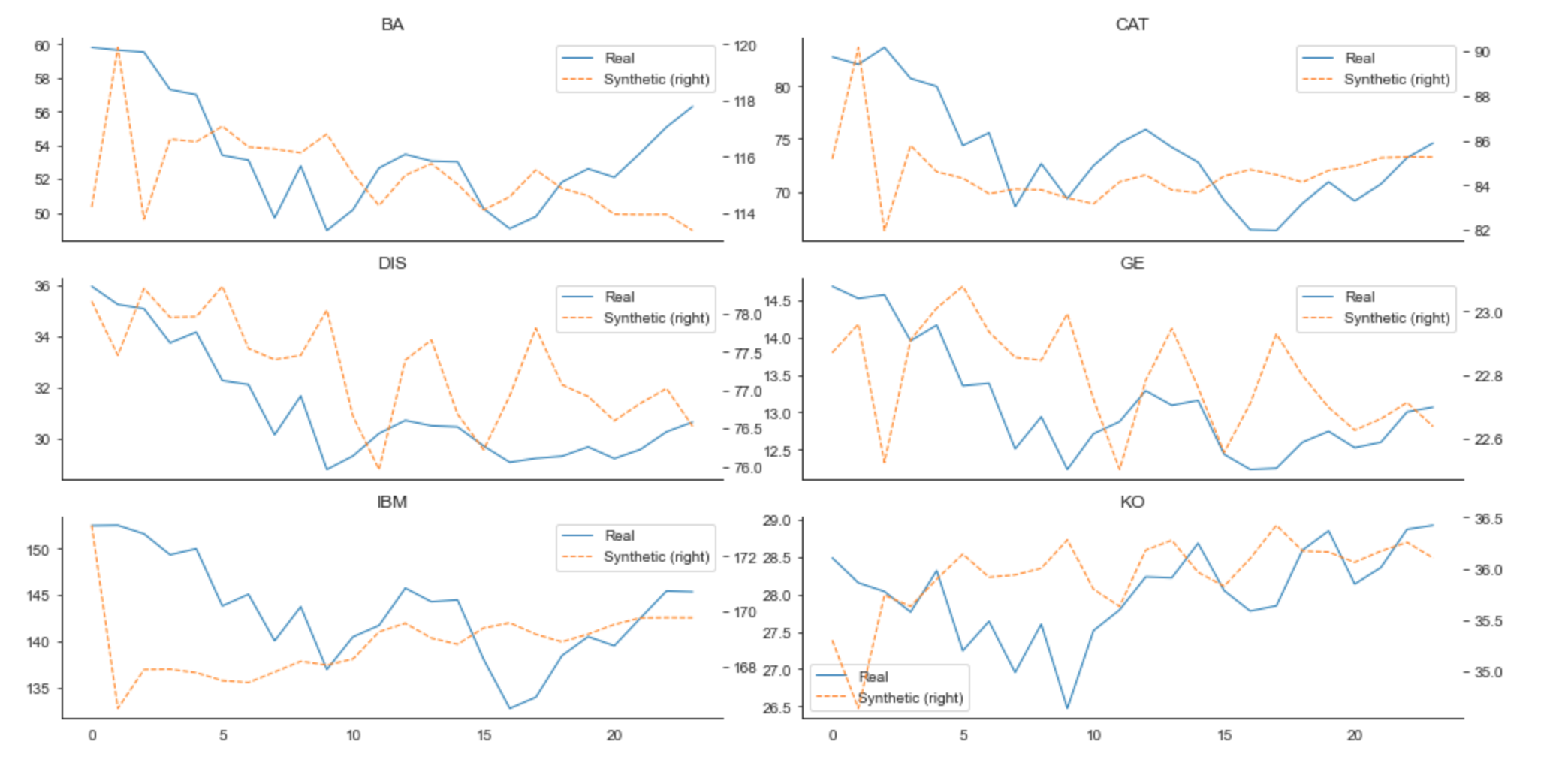
Evaluating Synthetic Time-Series Data
In terms of evaluating the quality of synthetic data generated, the TimeGAN authors use three criteria:
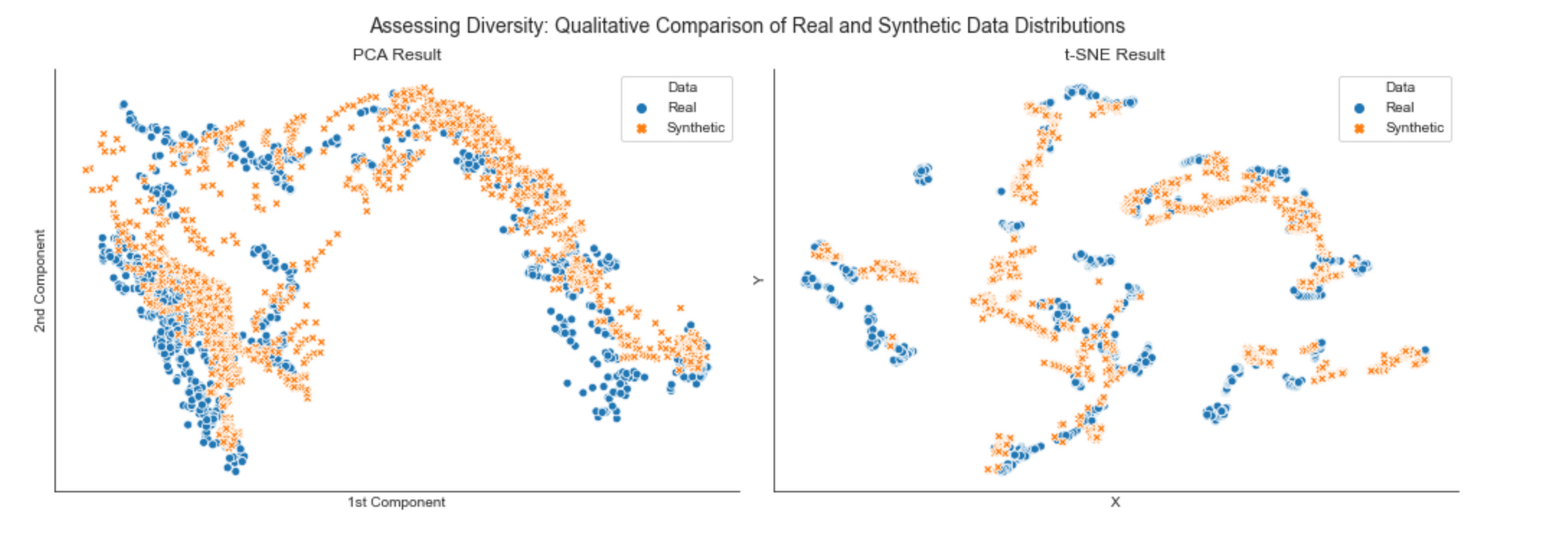
1. Diversity: the distribution of the synthetic data should roughly match the real data. Below we can see diversity is evaluated using two dimensionality reduction techniques—PCA and t-SNE—to evaluate how closely the distribution of synthetic data matches the original data:
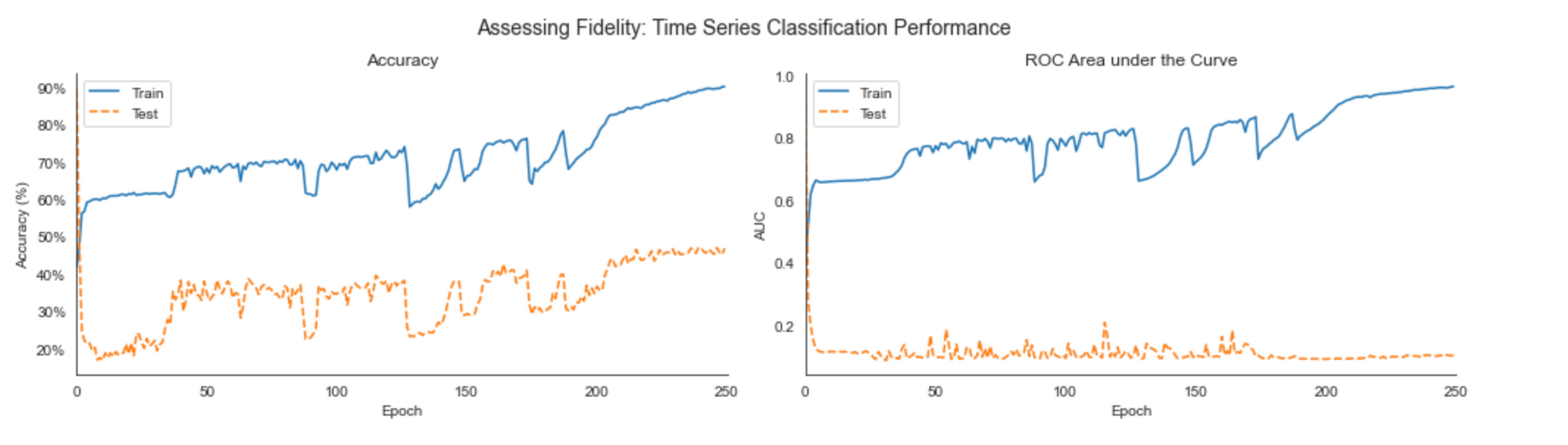
2. Fidelity: The sample series should be indistinguishable from the real data. To evaluate this, we use the test error (accuracy & ROC analysis) of a time-series classifier such as a 2-layer LSTM:
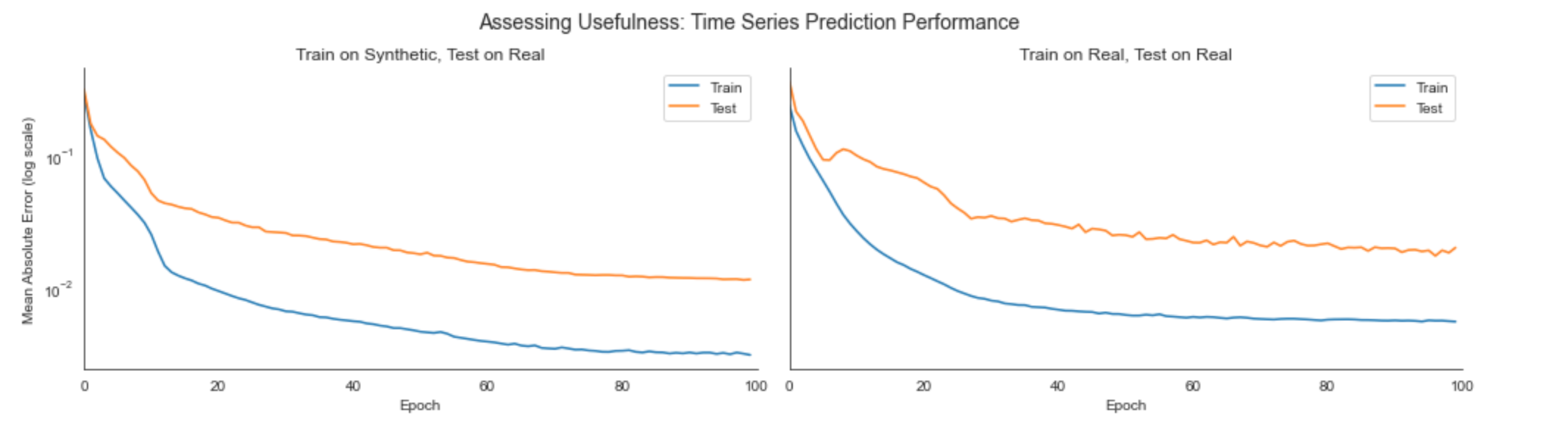
3. Usefulness: Finally, the synthetic data should be just as useful as the real data for solving predictive tasks. To evaluate this we can compare the test errors of a time series prediction model that is trained on either real or synthetic data:
Summary: Synthetic Financial Data with GANs
A key insight from training deep neural networks is that their predictive performance generally continues to improve with more data. As a survey from Cognilytica highlighted, however, quality data is not always available:
The biggest barrier to AI adoption is insufficient quantity or quality of data, followed by limited availability of AI talent and skills.
In order to overcome the limitations of data scarcity, privacy, and costs, GANs for generating synthetic financial data may prove to be essential in the adoption of AI.


