

In our previous articles on fine-tuning GPT-3, we discussed how to build a custom Q&A bot, how to build an earnings call transcript assistant, and how to build an IPO research assistant.
In this article, let's shift our focus to crypto assets and fine-tune GPT-3 on an additional body of knowledge and train it to answer questions factually based on said knowledge.
If you've tried ChatGPT at all, you know the reason that fine-tuning GPT-3 is required is that despite it's astonishing language generation capabilities, the base model can often be totally inaccurate when it comes to factual information.
As the docs highlight:
Base GPT-3 models do a good job at answering questions when the answer is contained within the paragraph, however if the answer isn't contained, the base models tend to try their best to answer anyway, often leading to confabulated answers.
Also, given the fact that GPT-3 is only trained on data until 2021 and doesn't have internet browsing access, this makes factual Q&A about recent events impossible out of the box.
This is where GPT-3 fine-tuning comes into play.
My first thought was to build a whitepaper research assistant, which was quite easy to do, although for many crypto assets I noticed a lot of this information was already available in ChatGPT. For example, below you can see I trained GPT-3 on the bitcoin whitepaper:
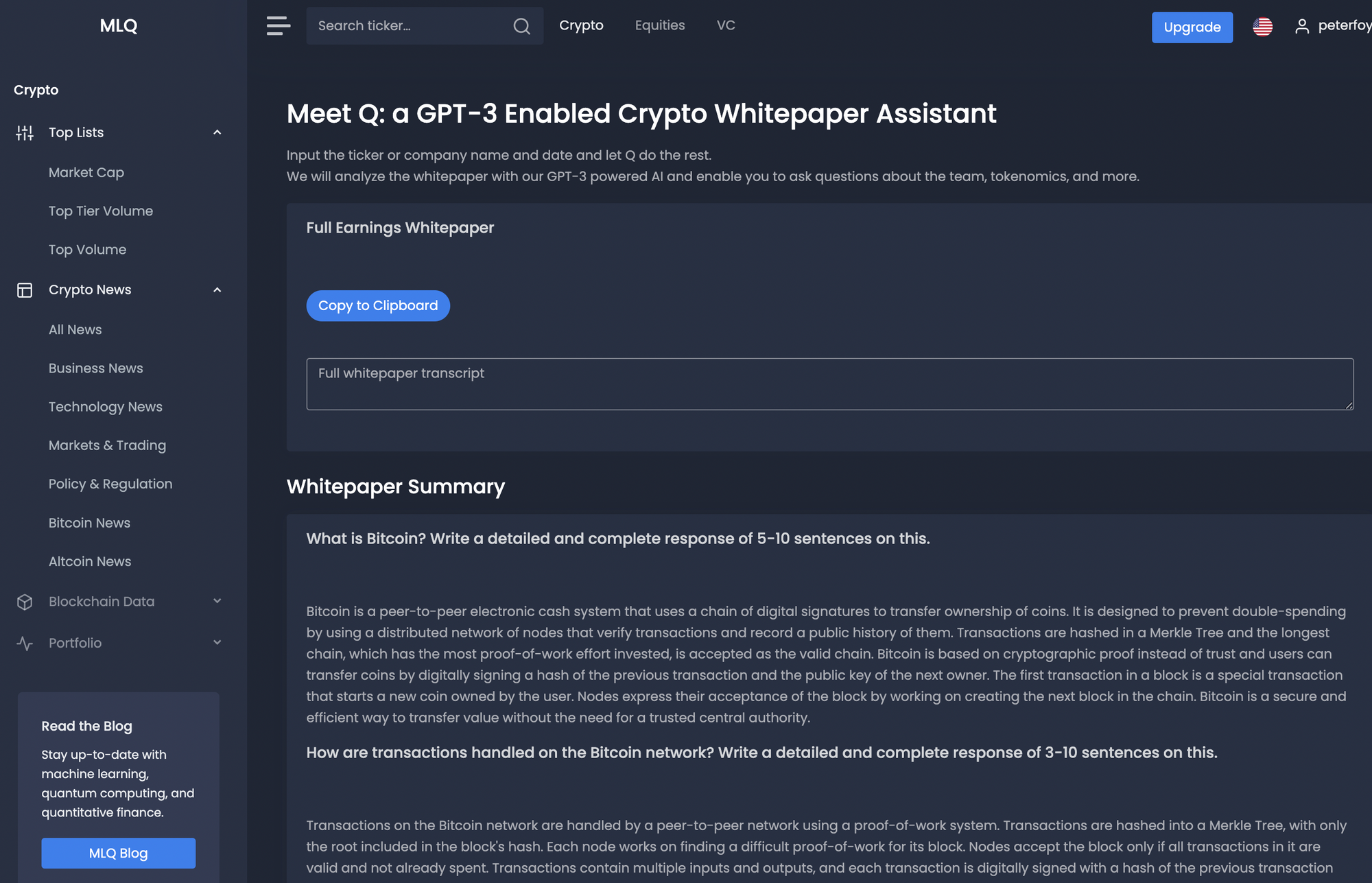
There is certainly still value in training a custom Q&A whitepaper assistant that answers 100% factually since we don't always know if GPT-3 responses are accurate or if it's just "hallucinating" i.e. answering incorrectly.
Despite the value in training GPT-3 on whitepapers, I decided to fine-tune GPT-3 on crypto events that took place after 2021 that I knew the base model wouldn't have knowledge.
The perfect example of a major event that took place after 2021 is, of course...the Merge. As we can see below, ChatGPT isn't able to answer definitively what the Merge is, when it took place, and so on.

Ok now we've defined the problem, the steps I need to build this fine-tuned GPT-3 crypto research assistant take include:
- Step 1: Get the data
- Step 2: Preprocessing the data for fine-tuning
- Step 3: Compute the document & query embeddings
- Step 4: Find similar document embeddings to the query embeddings
- Step 5: Add relevant document sections to the query prompt
- Step 6: Answer the user's query based on relevant document context
- Step 7: Prompt engineering to create an Ethereum Upgrade report summary
Also, if you want to see how you can use the Embeddings & Completions API to build simple web apps using Streamlit, check out our video tutorials below:
- MLQ Academy: Create a Custom Q&A Bot with GPT-3 & Embeddings
- MLQ Academy: PDF to Q&A Assistant using Embeddings & GPT-3
- MLQ Academy: Build a YouTube Video Assistant Using Whisper & GPT-3
- MLQ Academy: Build a GPT-3 Enabled Earnings Call Assistant
- MLQ Academy: Building a GPT-3 Enabled App with Streamlit
Step 1: Get the data
Since we want the most accurate and up-to-date information, the best place is obviously the Ethereum docs on the Merge.
Step 2: Data preprocessing for GPT-3 fine-tuning
The next step is to preprocess the data by splitting the text into subsections will be used for document embedding. As OpenAI suggests:
Sections should be large enough to contain enough information to answer a question; but small enough to fit one or several into the GPT-3 prompt. We find that approximately a paragraph of text is usually a good length, but you should experiment for your particular use case.

Stay up to date with AI
Step 3: Compute the document & question embedding
The next step is to create an embedding vector for each section of our preprocessed dataset using the OpenAI Embeddings API. As OpenAi writes:
An embedding is a vector of numbers that helps us understand how semantically similar or different the texts are. The closer two embeddings are to each other, the more similar are their contents
Aside from document embeddings, we also need to compute the query embeddings so that we can match them with the most relevant document sections.
To compute these vectors, we're going to the following functions from this OpenAI notebook:
get_embeddingget_doc_embeddingget_query_embeddingcompute_doc_embeddings
Now that we have our document data split into sections and encoded into embedding vectors, the next step is to use these embeddings to answer the user's question.
Step 4: Retrieve similar document & query embeddings
With our document and query embeddings, in order to answer the user's question we first need to retrieve similar document sections related to the question.
To do this, we're going to calculate the similarities with the vector_similarity function from the notebook.
Then, we're going to use the order_document_sections_by_query_similarity function to find the query embedding for the given question, and compare it to the document embeddings to retrieve the most relevant sections. This returns a list of relevant document sections sorted in descending order.
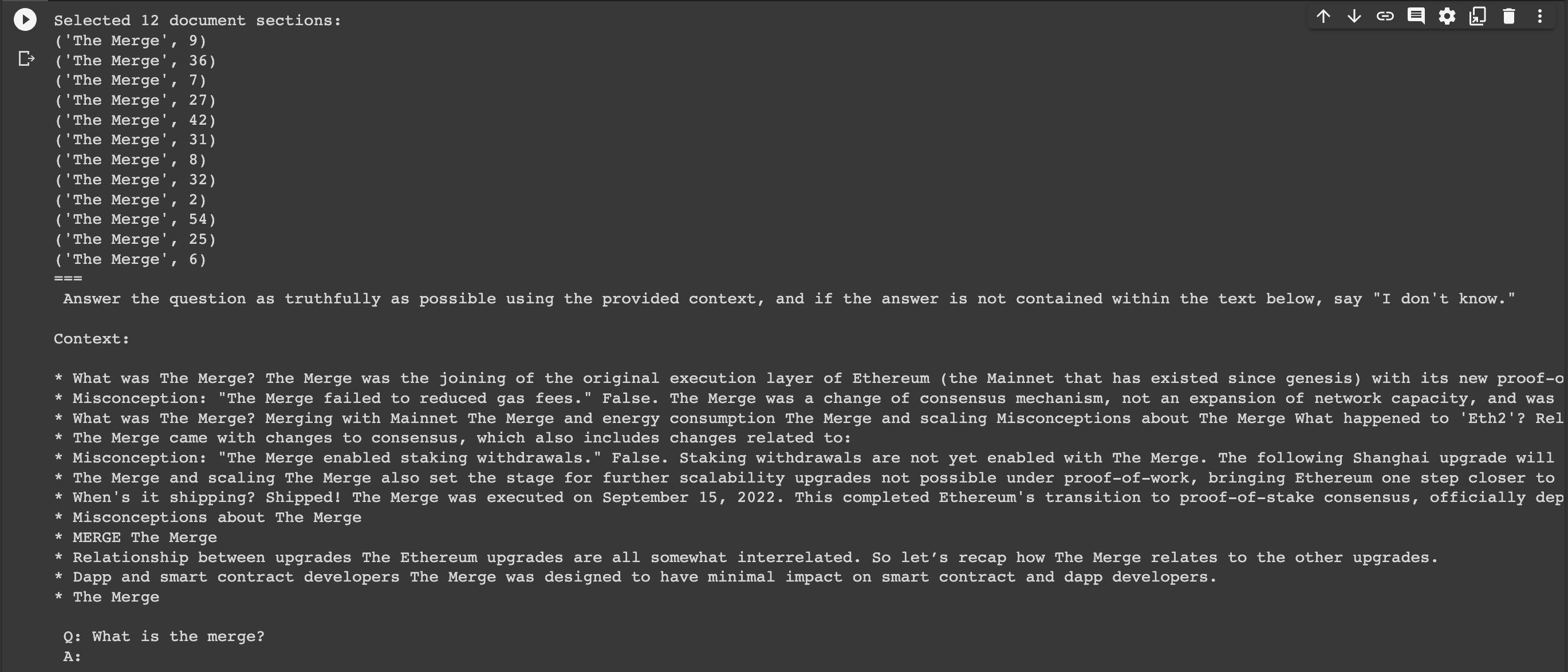
Here we can see an example of the retrieved document sections for the question "What is the Merge?"
order_document_sections_by_query_similarity("What the merge?", context_embeddings)[:5]
Step 5: Add relevant document sections to the query prompt
Now that we retrieved relevant document sections for the user's question, we need to construct a prompt that contains this information.
To add relevant context to the query prompt we'll use the construct_prompt function from the notebook:
prompt = construct_prompt(
"what is the Merge?",
context_embeddings,
df
)
print("===\n", prompt)Below we can see the relevant document sections for the question "What is the Merge?":
Okay last step, we need to answer the question based on this document context.
Step 6: Answer the user's question based on relevant document context
In order to actually answer the user's question with relevant document context, we need to use the Completions API.
Since we want it to answer factually and not get "creative", we'll set the temperature parameter to 0.
Next, all we need to do is use the answer_query_with_context function from the notebook and we get the following response
answer_query_with_context("What was the revenue for the quarter", df, context_embeddings)The Merge was the joining of the original execution layer of Ethereum (the Mainnet that has existed since genesis) with its new proof-of-stake consensus layer, the Beacon Chain. This eliminated the need for energy-intensive mining and instead enabled the network to be secured using staked ETH. The Merge also set the stage for further scalability upgrades not possible under proof-of-work, bringing Ethereum one step closer to achieving the full scale, security and sustainability outlined in its Ethereum vision. It was designed to have minimal impact on smart contract and dapp developers, and was executed on September 15, 2022, completing Ethereum's transition to proof-of-stake consensus, officially deprecating proof-of-work and reducing energy consumption by ~99.95%.
Nice work GPT-3.
Step 7: Prompt engineering to build an Ethereum Upgrade summary
As a final step, we did some more prompt engineering in order to output a complete summary of Ethereum Upgrades: The Merge, The Beacon Chain, and Sharding:
 MLQ
MLQ
Summary: Building a GPT-3 Enabled Research Assistant
In this article, we saw how we can fine-tune GPT-3 to be a research assistant by training it on an additional body of knowledge with the Embeddings API, and then answering questions factually with the Completions API.
Of course, this AI is still fine-tuned on a tiny dataset to test the idea of a crypto research assistant, but as a more complete solution, you could train it on the documentation of all major crypto assets and then have it write complete research reports, come up with portfolio allocation ideas, and so much more...




